

PayPal Data Scientist Interview Guide (2025): Questions, Process & Preparation Tips


Introduction
Preparing for a PayPal data scientist interview means stepping into one of the most data intensive environments in global fintech. PayPal processes billions of transactions every year across more than 400 million active accounts, which makes data science essential for fraud detection, risk modeling, payments optimization, and growth analytics.
Because these decisions directly impact user trust and financial safety, PayPal hires data scientists with strong analytical rigor, sharp product intuition, and the ability to influence high stakes decisions. Every improvement to a model or experiment can shape millions of transactions worldwide, which is why the data scientist interview process is both selective and highly technical.
In this guide, you will learn how the PayPal data scientist interview works, the types of questions you can expect, preparation strategies used by successful candidates, and the salary benchmarks for data science roles at PayPal. Whether you are early in your preparation or refining your final study plan, this guide will help you navigate every stage of the process.
What Does a PayPal Data Scientist Do
PayPal data scientists blend analytical depth with strong risk and product intuition. They help teams understand how users transact, where friction occurs in the payments flow, and how to protect the platform from fraud while improving authorization rates. Much of the work involves partnering with product, engineering, and risk specialists to solve open ended problems using structured analysis, experimentation, and responsible model design.
Core responsibilities include:
- Building fraud detection, anomaly detection, and risk scoring models for high stakes financial decisions
- Designing and evaluating experiments for checkout flows, authentication prompts, and new risk rules
- Analyzing merchant and user behavior to identify friction, system anomalies, or emerging fraud patterns
- Writing efficient SQL to query large scale transactional and payments datasets
- Developing event based and time series metrics for monitoring authorization rate, fraud rate, and dispute patterns
- Investigating sudden metric shifts across geographies, devices, issuers, or merchant segments
- Collaborating with PMs, engineers, and risk teams to translate ambiguous problems into measurable analyses
- Presenting insights through dashboards, deep dives, and narrative documents that influence product and policy decisions
- Ensuring models are monitored for drift, fairness, and operational reliability once deployed
PayPal Data Scientist Interview Process
The PayPal data scientist interview process evaluates your ability to analyze complex payment patterns, build reliable models, communicate insights clearly, and work effectively within cross functional teams. The process usually includes several rounds that focus on SQL, machine learning fundamentals, applied analytics, fraud and risk reasoning, and behavioral alignment with PayPal’s values. Most candidates complete the full loop within three to six weeks depending on team availability and role level.
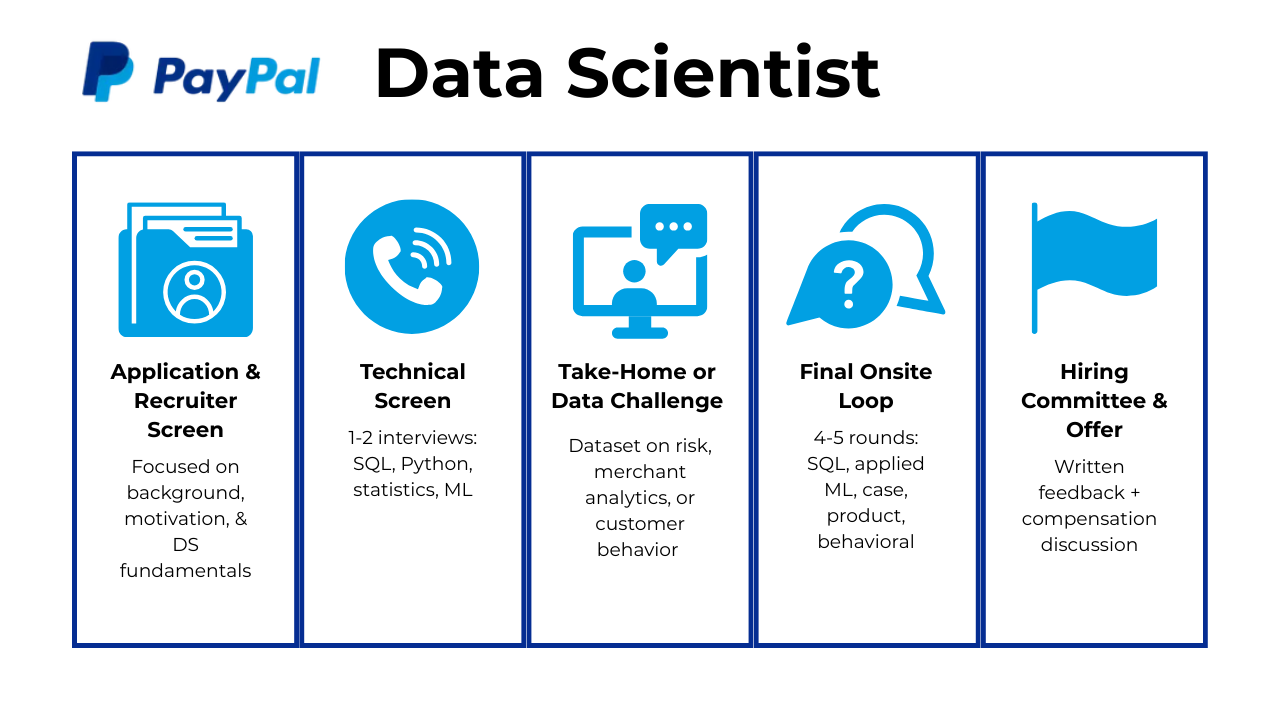
Below is a breakdown of each stage and what PayPal interviewers look for throughout the process.
Application And Resume Screen
During the application review, PayPal recruiters look for experience working with data at scale, strong SQL and Python skills, knowledge of machine learning techniques, and previous exposure to domains like payments, fraud detection, or risk modeling. Resumes that highlight measurable business impact, especially related to model performance or decision improvements, tend to stand out. You should also emphasize experience with experimentation, feature engineering, or anomaly detection since these align strongly with PayPal’s day to day work.
Tip: Quantify every achievement using metrics like recall lift, fraud reduction, conversion gains, or latency improvements. Numbers make your impact clear and increase your chances of passing the initial screen.
Initial Recruiter Conversation
The recruiter call is a short discussion focused on your background, motivation for PayPal, and understanding of data science fundamentals. Recruiters use this call to confirm your experience with relevant tools, your familiarity with applied machine learning, and whether you have worked on projects that required high levels of analytical rigor. They may also ask about location preferences, timeline, and salary expectations. This stage is non technical but communicates whether you are a strong match for the role and team.
Tip: Prepare a clear two minute story that connects your past experience to why you want to work on risk, payments, or experimentation at PayPal.
Technical Screen
The technical screen typically includes one or two interviews that focus on SQL, Python coding, statistics, and practical machine learning. You may be asked to join tables, build window function queries, analyze anomalies in transactional data, design experiments, or walk through the modeling pipeline you used on a past project. Interviewers often present small case scenarios, such as investigating a spike in fraudulent transactions or designing features for a risk scoring model. This round evaluates both problem solving and communication clarity.
Tip: Practice writing SQL and Python in a plain text environment without autocomplete since PayPal technical screens usually use shared documents.
Take Home Assignment Or Data Challenge
Some teams, especially those working in risk, merchant analytics, or customer behavior modeling, include a take home assignment. These challenges often involve a dataset where you will identify anomalies, build a baseline model, compare feature importance, or propose next steps for improving accuracy and stability. Your submission is evaluated not only on correctness but also on reasoning, clarity, and ability to communicate trade-offs. A clean, concise write-up is essential.
Tip: Treat the assignment like a real business deliverable by clearly explaining assumptions, limitations, and how you would iterate if you had more time.
Final Onsite Interview
The final onsite loop is the most in depth stage of the PayPal data scientist interview process. It typically includes four to five interviews, each lasting about 45 to 60 minutes. These rounds evaluate how you solve real problems related to fraud detection, payments optimization, experimentation, and product analytics. Interviewers look for structured thinking, clear communication, and strong reasoning through ambiguity.
SQL and data analysis round
You will write queries that work with large and sometimes messy transactional datasets. Expect tasks like identifying suspicious behavior patterns, comparing authorization rates across segments, or computing rolling metrics with window functions. Interviewers assess your ability to query cleanly, handle edge cases, and extract insights that could influence real decisions at PayPal.
Tip: Before writing any query, restate the problem in your own words and outline your approach. This shows strong analytical habits and reduces the chance of misinterpretation.
Applied machine learning round
This interview focuses on end-to-end modeling. You may be asked to design a fraud detection pipeline, choose features for a risk model, interpret model outputs, or explain how to monitor performance over time. PayPal values practical ML thinking, so expect questions about trade-offs between precision and recall, dealing with imbalanced datasets, and model drift.
Tip: Use examples from your past work to illustrate how you approached similar modeling challenges and what you learned from them.
Experimentation and case study round
You may be asked to design an experiment for improving payment conversion, analyze a decline in authorization rates, or investigate an unexpected spike in dispute claims. These cases test how you break down ambiguous problems, define metrics, and reason through possible causes. Interviewers care more about your structure and logic than a perfect solution.
Tip: Start by clarifying the objective, the users involved, and the key metrics. Framing the problem correctly is often half the work.
Product and business strategy round
This round examines your ability to connect technical work to PayPal’s broader goals. You might discuss how a new feature affects user trust, how improved fraud detection changes merchant experience, or which metrics matter most in cross border payments. You will also explain how you would collaborate with engineers, PMs, and risk teams.
Tip: Tie every recommendation to a measurable business outcome. PayPal interviewers value candidates who show awareness of financial and user impact.
Behavioral and collaboration round
Interviewers assess how you communicate, handle setbacks, and work with cross functional partners. Expect questions about conflict resolution, working under pressure, receiving feedback, or owning projects end to end. PayPal values collaboration, empathy, and clarity in a fast moving environment.
Tip: Use the STAR method to keep your stories focused and clear. Emphasize the result and what you learned from the experience.
Hiring Committee And Offer
After the onsite, interviewers submit written feedback separately. A hiring committee then reviews your performance across all rounds and evaluates your technical ability, communication strength, and alignment with PayPal’s culture. If approved, the team proposes a level and compensation package that reflects your experience and the role requirements. Candidates may also be matched to a specific product, risk, or analytics team based on interviewer feedback and preferences.
Tip: If you have multiple team interests, communicate them early since PayPal often considers team matching during the final stages.
Struggling with take-home assignments? Get structured practice with Interview Query’s Take-Home Test Prep and learn how to ace real case studies.
PayPal Data Scientist Interview Questions & Answers
The PayPal data scientist interview includes a mix of SQL, analytics, experimentation, product reasoning, and machine learning depth. These questions evaluate how well you understand real world data challenges such as detecting fraud patterns, analyzing transaction flows, improving conversion, and building reliable models in high stakes financial systems. The goal is not only to test your technical ability but also to understand how you approach ambiguity and communicate insights clearly.
SQL And Analytics Interview Questions
In this part of the interview, PayPal focuses heavily on your ability to work with transactional data at scale. SQL questions often involve fraud detection patterns, window functions, segmentation analysis, or anomaly identification. The goal is to see whether you can structure data, interpret patterns accurately, and think through data quality issues that appear in payments and risk environments.
Read more: Top Data Science SQL Interview Questions: From Basics to Advanced
Write a query to detect overlapping subscription periods
This question tests your ability to identify time range conflicts using self joins, which is important for catching billing inconsistencies or double charges. To answer it, you would join the table to itself on customer ID where one subscription’s start date occurs before another subscription’s end date and also ensure the other subscription’s start date occurs before the first one ends. A proper solution also filters out identical records using
subscription_id != other.subscription_id.Tip: Handle open ended subscriptions by using
COALESCE(end_date, CURRENT_DATE)so ongoing periods are compared correctly.-
This question evaluates your ability to use window functions for behavioral metrics. You can calculate consecutive visit streaks by comparing event dates with
LAG()and resetting counts when a break occurs, then aggregate by user to find the longest streak. This problem tests analytical thinking, partition logic, and efficient event ordering, all key in product analytics pipelines.Tip: Emphasize handling edge cases where users skip days or have multiple events on the same day since both can break streak logic if not managed properly.
Write a query to identify users who triggered more than three chargebacks in the last 60 days.
This question tests your ability to work with time based filtering and group level aggregation. It also relates to PayPal’s real risk scenarios where repeated chargebacks may indicate account takeover or suspicious merchant activity. To answer this, explain how you would filter transactions within the time window, group by user, count chargebacks, and select only those above the threshold.
Tip: Mention how you would validate the data for duplicate events or missing timestamps before finalizing the query.
Find the month_over_month change in revenue for the year 2019.
This question tests time-based windowing. You’re looking to measure growth momentum by comparing revenue each month to the previous one. To solve this, group revenue by month using
DATE_TRUNC('month', order_date)and useLAG(SUM(revenue)) OVER (ORDER BY month)to compute the difference, then divide by the previous month’s revenue for a percent change. This is one of the most common metrics in finance and e-commerce analytics.Tip: Clarify that you’d filter out the first month since it has no prior comparison, since such clean handling of edge cases always impresses interviewers.
Head to the Interview Query dashboard to practice the full set of PayPal’s interview questions. With built-in code testing, performance analytics, and AI-guided tips, it’s one of the best ways to sharpen your skills for PayPal’s data interviews.
How would you find merchants with a sudden spike in failed payments compared to the previous week?
This question evaluates your use of window functions and comparisons across time periods. In a payments platform like PayPal, weekly spikes can signal outages, integration issues, or fraud attempts. Explain how you would calculate failure counts for two periods and compare them using a join or window function.
Tip: Describe how you would check for merchant seasonality since spikes can sometimes be normal business variation.
Write a query to calculate the rolling seven day authorization rate for each merchant.
This question tests your use of window functions to create rolling metrics, which PayPal relies on for fraud monitoring and system health checks. The answer involves calculating daily approved and total attempts, then using a seven day window with
SUM() OVER (PARTITION BY merchant ORDER BY date ROWS BETWEEN 6 PRECEDING AND CURRENT ROW)to compute rolling totals before taking the ratio.Tip: Mention why rolling windows smooth out volatility in highly variable financial data.
How would you detect transactions with duplicate charges within a short time window?
This question assesses your understanding of identifying near duplicates using self joins or window functions. PayPal uses similar approaches to detect user experience issues or fraud scripts. Explain how to partition by user, sort by timestamp, and compare adjacent transactions for matching amount and merchant.
Tip: Point out that thresholds for what counts as a duplicate should be tested against real data distributions.
Watch Next: Meta SQL Data Scientist Interview: Calculate Notification Conversion Rates
In this mock data scientist interview, Vivian, a lead data scientist tackles a real SQL problem from Meta along with Chinmaya as the interviewer, determining which type of notification drives the most conversions. The video walks through analyzing multiple tables, building a logical attribution model, and writing clean, efficient SQL using CTEs and window functions. It’s a great resource for learning how to approach complex, ambiguous SQL interview questions and explain your reasoning clearly under pressure, which are key skills for a PayPal data science interview.
A/B Testing And Experimentation Interview Questions
PayPal experiments frequently on checkout flows, risk scoring strategies, authentication prompts, and merchant tools. These questions examine your ability to design clean experiments, interpret results properly, and think critically about metric validity in a financial environment where false positives can carry real cost.
Read more: Top 60 Statistics & A/B Testing Interview Questions
How would you design an experiment to test a new fraud scoring model?
This question evaluates your understanding of experiment design with safety constraints, since changes to fraud scoring models directly influence revenue and loss rates at PayPal. A strong answer explains using a controlled holdout group, monitoring high risk segments independently, and defining primary metrics such as fraud rate, false positive rate, and authorization lift. You should discuss guardrails for user experience, real time monitoring, and stopping rules depending on risk thresholds.
Tip: Highlight how you would keep the experiment small at first to minimize financial exposure.
-
This question tests your understanding of external validity and regression toward the mean. A realistic answer explains that the observed five percent lift in an experiment usually shrinks during rollout due to population differences, novelty effects, traffic mix shifts, or overfitting to early test segments. The real world impact could be smaller because experiment conditions are controlled, but it may occasionally be larger if device types or geographies not included in the test benefit more from the change.
Tip: Mention that PayPal teams regularly validate experiment results with phased rollouts to measure real world performance.
-
This question evaluates your ability to apply hypothesis testing to proportion based metrics like CTR. The answer includes setting up null and alternative hypotheses, calculating standard errors for both groups, and using a z test or two proportion test to compute the p value. You would then compare the p value against a significance threshold and check confidence intervals to ensure the effect is practically meaningful, not just statistically significant.
Tip: Discuss the need to confirm traffic randomization and sample balance before trusting the result.
Head to the Interview Query dashboard to practice the full set of PayPal’s interview questions. With built-in code testing, performance analytics, and AI-guided tips, it’s one of the best ways to sharpen your skills for PayPal’s data interviews.
How would you handle an experiment that shows conflicting results across segments?
This question tests your ability to work with heterogeneous treatment effects, which are common in payment and risk models. You should explain how you would re segment by merchant type, region, payment method, device, or risk tier, and compare confidence intervals to identify whether segment differences are meaningful. Many PayPal experiments require segment aware decisions, such as launching first for low risk merchants or high volume regions.
Tip: Emphasize that conflicting results are a signal to run follow up experiments, not to discard the original test completely.
-
This question tests your ability to connect experiment structure to business outcomes. A strong answer explains randomizing users or accounts into control and treatment, measuring conversion rate, retention risk, revenue per user, and refund or cancellation behavior. You would calculate lift in net revenue, analyze elasticity of demand, and verify guardrails to ensure the price increase does not degrade payment success or customer satisfaction.
Tip: Mention that PayPal style experiments should also track chargebacks or dispute rates when price changes may influence user behavior.
Looking for hands-on problem-solving? Test your skills with real-world challenges from top companies. Ideal for sharpening your thinking before interviews and showcasing your problem solving ability.
Product, Behavioral, And Scenario Based Interview Questions
These interviews explore your judgment, clarity of reasoning, and alignment with PayPal’s mission of secure and frictionless payments. You will be tested on how you communicate, resolve ambiguity, work with cross functional stakeholders, and make decisions that balance growth and risk.
What makes you a good fit for our company?
This question tests how well you understand PayPal’s mission, culture, and the responsibilities of a data scientist working in a global payments ecosystem. Strong candidates connect their analytical strengths to PayPal’s focus on trust, security, risk reduction, and seamless payments across millions of users and merchants.
Example: “I am drawn to PayPal because of its mission to build trust and enable secure digital payments worldwide. In my previous role, I built anomaly detection models that reduced review times and improved risk team efficiency by 18 percent. I enjoy solving high impact problems with data, and I believe my mix of modeling experience and cross functional collaboration aligns closely with PayPal’s values.”
Tip: Show that you understand PayPal’s role in global payments and highlight experience with fraud, risk, experimentation, or large scale data problems.
Tell me how you would investigate a sudden decline in global payment authorization rates.
This question tests structured investigation and your ability to diagnose issues in high stakes financial systems. A strong answer explains segmenting authorization data by region, issuer, device, and merchant category, reviewing recent code releases or risk rule changes, and partnering with risk engineering and network teams to identify system wide anomalies.
Example: “In a past payments project, we saw a sudden drop in authorization rates. I segmented results by issuer and geography, which quickly revealed that the decline was isolated to one issuing bank after a weekend system update. Working with engineering and the partner bank, we resolved the issue within hours and restored normal performance.”
Tip: Validate whether the issue is due to data quality or system outages before analyzing user behavior.
How would you prioritize issues if multiple fraud alerts triggered at the same time?
This question evaluates your decision making under pressure and your understanding of financial risk severity. You should explain prioritizing based on potential dollar loss, number of users impacted, likelihood of ongoing fraud, and whether alerts relate to confirmed attack vectors.
Example: “When several fraud alerts fired simultaneously at my previous company, I ranked them by financial exposure and number of users affected. One alert showed rapid card testing activity, so we escalated it immediately. Lower severity alerts were reviewed afterward once the primary risk was contained. This approach kept losses minimal while maintaining response discipline.”
Tip: Referencing clear escalation protocols shows that you can operate effectively in real time fraud scenarios.
What metrics would you use to measure the success of a new merchant onboarding flow?
This question tests product intuition and your ability to define metrics aligned with business and user needs. You should mention tracking onboarding completion rate, verification pass rate, time to activation, drop off locations, and early merchant performance indicators such as first transaction success. PayPal relies on these metrics to ensure onboarding is smooth, compliant, and optimized for merchant conversion.
Example: “In my previous role, we redesigned a merchant onboarding flow and tracked completion rate, verification success, and activation time. By mapping drop off points, we identified a verification step causing 30 percent abandonment. After simplifying that step, onboarding completion improved significantly within two weeks.”
Tip: Emphasize how early funnel metrics predict long term merchant engagement and trust.
Describe a time you had to work with a difficult stakeholder.
This question evaluates your communication style, your ability to build alignment, and how you handle disagreements with partners who may have different priorities or levels of technical fluency. At PayPal, where data scientists frequently partner with risk, compliance, and product teams, demonstrating patience and influence is essential.
Example: “A PM once strongly disagreed with my analysis because it contradicted their hypothesis about a feature’s impact. I walked them through the data sources, assumptions, and logic in a clear side by side breakdown. Once the reasoning became intuitive, we aligned on a revised experiment that later improved conversion by 12 percent. That experience taught me how transparency and empathy help turn conflict into shared decision-making.”
Tip: Focus on how your communication changed the dynamic, not just how the disagreement was resolved.
Head to the Interview Query dashboard to practice the full set of PayPal’s interview questions. With built-in code testing, performance analytics, and AI-guided tips, it’s one of the best ways to sharpen your skills for PayPal’s data interviews.
What are some effective ways to make data more accessible to non-technical people?
This question tests your ability to simplify complexity and make data useful for stakeholders who rely on insights but may not speak in models or metrics. PayPal’s teams in operations, customer support, and merchant services often require clear takeaways rather than technical detail. Strong candidates show they can structure information visually, remove jargon, and tie insights directly to decisions.
Example: “In my last role, I supported a customer operations team that struggled to interpret fraud-related signals from our dashboards. I redesigned the dashboard using simpler KPIs, added color-coded alerts, and wrote short plain-language descriptions for each metric. I also held a brief walkthrough meeting where I explained how to use the dashboard to prioritize cases. After the update, the team reported a 20 percent reduction in investigation time because they understood exactly what the data meant.”
Tip: Show that you think beyond charts and focus on building shared understanding through clarity, structure, and context.
Machine Learning And Technical Depth Interview Questions
These questions evaluate your applied ML knowledge, ability to work with imbalanced financial data, and understanding of how to deploy models responsibly. PayPal expects candidates to discuss pipelines, monitoring, drift, bias, and real world reliability.
Read more: Top 50 Machine Learning System Design Interview Questions
-
This question tests whether you understand the geometry behind PCA and clustering, which helps reveal structure in high dimensional financial data. PCA identifies directions of maximum variance, and the first few components often align with cluster centroids, making k-means distance calculations more stable and faster. Applying PCA before clustering reduces noise, removes correlated features, and improves performance in pipelines where PayPal analyzes behavioral or transactional patterns at scale.
Tip: Mention that PCA can prevent k-means from being overly influenced by high variance but irrelevant dimensions.
How would you compute precision and recall from a 2-D confusion-matrix-style list in Python?
This tests both your understanding of classification metrics and your ability to implement them cleanly. You should explain validating the matrix structure, extracting true positives, false positives, and false negatives for each class, and computing precision as TP / (TP + FP) and recall as TP / (TP + FN) with safeguards for division by zero. A robust answer notes that vectorized NumPy solutions work well for production pipelines and that PayPal uses similar metrics to evaluate fraud models.
Tip: Mention verifying outputs using
classification_report()to demonstrate practical debugging skills.
Head to the Interview Query dashboard to practice the full set of PayPal’s interview questions. With built-in code testing, performance analytics, and AI-guided tips, it’s one of the best ways to sharpen your skills for PayPal’s data interviews.
-
This question evaluates your understanding of kernel theory and practical implementation challenges. You should discuss ensuring the kernel satisfies Mercer’s condition, being careful about dimensionality expansion, and avoiding kernels that produce non positive semi definite Gram matrices. Validation can include checking eigenvalues of the Gram matrix and tuning kernel hyperparameters through cross validation to ensure stable behavior on real financial datasets.
Tip: Mention the importance of scaling inputs before applying kernels since SVM performance is sensitive to feature magnitude.
-
This question tests your knowledge of monitoring ML systems once deployed. A strong answer discusses tracking ROC AUC, precision at k, false negative rate, and drift in prediction distributions over time, since PayPal style models require stability under changing behavior patterns. You should also mention using rolling windows, alert thresholds, and canary deployments to ensure the classifier remains reliable across cohorts.
Tip: Emphasize custom thresholds because operational models often need stricter controls than offline evaluations.
-
This question evaluates your ability to design ML workflows for domains like fraud detection where positive cases are rare. You should explain techniques such as class weighting, SMOTE or undersampling, anomaly detection alternatives, and using metrics like precision recall instead of accuracy. PayPal relies on these techniques to avoid models that miss fraudulent transactions or generate too many false positives for merchants.
Tip: Note that you would monitor feature stability and drift because imbalance can amplify small distributional changes over time.
Need 1:1 guidance on your interview strategy? Explore Interview Query’s Coaching Program that pairs you with mentors to refine your prep and build confidence.
How To Prepare For A PayPal Data Scientist Interview
Preparing for the PayPal data scientist interview is about more than reviewing SQL syntax or memorizing machine learning definitions. You are preparing for a role that directly influences user trust, payment security, and merchant experience on one of the largest fintech platforms in the world. That means you need to blend technical sharpness with strong reasoning, risk awareness, product intuition, and clear communication.
Read more: How to Prepare for Data Science Interviews
Think of it as preparing to analyze like a risk scientist, evaluate like a product strategist, and communicate like a trusted partner to engineering and compliance teams. Below is a step-by-step guide to help you show up confident and ready.
Study real payment system workflows from end to end
PayPal expects candidates to understand how money actually moves: funding sources, card networks, processors, authorization flows, chargebacks, and dispute lifecycles. Review how each stage introduces different data patterns and failure points, because case interviews often hinge on whether you can reason through the business logic behind a metric shift.
Tip: Draw a simple payments flow diagram and practice explaining where data scientists intervene and why.
Learn how to evaluate trade offs between user friction and security
Many PayPal decisions balance false positives, fraud exposure, user friction, and regulatory constraints. Prepare to articulate how you weigh these trade offs rather than defaulting to “maximize accuracy.” Think about scenarios where improving safety creates friction or improving conversions increases risk.
Tip: Build a mental framework (impact, exposure, reversibility) to reason through trade offs quickly.
Get comfortable reading ambiguous, incomplete, or conflicting data
Payment systems often generate noisy logs, missing attributes, timestamp mismatches, and inconsistent identifiers. PayPal interviewers want to know how you think when the data is imperfect rather than clean. Practice with real world datasets where you must infer intent, reconstruct sequences, or reconcile mismatched identifiers.
Tip: Practice “data triage” by listing assumptions and validation steps before jumping into analysis.
Practice diagnosing silent failures and hidden system issues
Some of the hardest interview questions involve patterns that look like user behavior changes but actually come from upstream outages, third party processors, or configuration changes. Develop the habit of considering system explanations before user explanations.
Tip: Build a checklist for diagnosing any sudden metric shift: data quality, system logs, deploy history, upstream dependencies.
Learn to build monitoring and alerting logic, not just models
PayPal relies heavily on real time signals. Understand how you would track model drift, score distribution shifts, approval rate fluctuations, and fraud spikes. Practice explaining how you design dashboards, thresholds, and guardrails to ensure operational reliability.
Tip: Describe one example of monitoring you set up and how it prevented or caught an issue.
Strengthen your ability to translate complex decisions for compliance and regulatory teams
PayPal operates in a highly regulated environment. You may need to explain how a model works, why a feature matters, or what risk exposure a change creates. Prepare examples showing how you’ve explained complex reasoning to non technical stakeholders.
Tip: Practice summarizing a technical project in a format suitable for a compliance review or audit.
Demonstrate familiarity with fraud patterns, emerging attack vectors, and global payment trends
PayPal interviewers value candidates who understand the broader ecosystem. Spend time researching common fraud tactics, behavioral patterns during peak seasons, authentication best practices, and geographic differences in payment behavior.
Tip: Skim quarterly fintech or fraud industry reports and take notes on trends you can reference in conversations.
Run realistic mock interviews
Simulate a full mock interview loop with SQL, ML, case, and behavioral questions to strengthen your stamina and structure. After each mock, review where your reasoning drifted, where you hesitated, or where your explanations lacked clarity. Repetition builds confidence and highlights exactly what to refine.
You can use Interview Query’s Question Bank to practice PayPal style questions sourced from real candidates. For personalized guidance, Interview Query’s Coaching Program pairs you with mentors who can walk you through real cases, model reviews, and data challenges.
Tip: Track improvement across mocks like a dataset. Write down patterns in your mistakes so you can correct them quickly and consistently.
Want to build up your PayPal interview skills? Practicing real hands-on problems on the Interview Query Dashboard and start getting interview ready today.
Salary And Compensation For PayPal Data Scientists
PayPal’s compensation philosophy centers on rewarding technical depth, analytical impact, and the ability to support secure and seamless global payments. For data scientists, this often means competitive base pay, strong annual bonuses, and meaningful equity that grows with company performance. Your total compensation depends on your level, location, role type, and the team you join. Most candidates enter between mid level and senior depending on experience with fraud modeling, payments analytics, or large scale machine learning systems.
Tip: Clarify your level with your recruiter early in the process since PayPal’s leveling structure determines both your compensation range and your day to day responsibilities.
Average PayPal Data Scientist Salary Bands (2025)
| Level | Typical Role Title | Total Compensation Range (USD) | Breakdown |
|---|---|---|---|
| DS1 | Data Scientist I (Entry-Level) | $120K – $160K | Base $105K–$135K + Bonus + Equity |
| DS2 | Data Scientist II / Mid-Level | $150K – $200K | Base $120K–$150K + Bonus + RSUs |
| Senior DS | Senior Data Scientist | $180K – $260K | Base $140K–$175K + Significant Equity + Bonus |
| Staff DS | Staff or Lead Data Scientist | $230K – $320K+ | Base $160K–$200K + High RSUs + Bonus |
Note: These estimates are based on aggregated 2025 data from Levels.fyi, Glassdoor, TeamBlind, and Interview Query’s internal salary database. Actual offers vary by location (San Jose vs. New York vs. Austin vs. Remote), team (Risk, Payments, Credit, Commerce), and performance.
Tip: Always compare salary data from at least two sources before negotiating since fintech compensation varies widely based on risk exposure, business unit, and cost of living adjustments.
Average Base Salary
Average Total Compensation
How PayPal Structures Compensation
PayPal’s total compensation package typically includes four major components. Understanding each one helps you evaluate your offer and negotiate effectively.
| Component | What It Means | Notes |
|---|---|---|
| Base salary | Fixed annual pay aligned to fintech and data science market benchmarks | Typically the least flexible part of the offer, though varies by level and location |
| Annual performance bonus | Bonus tied to PayPal’s financial performance and your individual contribution | Data scientists commonly see target bonuses between 10% and 25% depending on level |
| Equity (RSUs) | Restricted Stock Units that vest over four years | Senior DS, Staff, and Risk-focused roles often receive higher equity grants and annual refreshers |
| Signing bonus or relocation assistance | One time payment for new hires or candidates relocating to key offices | More common for senior levels or hard to fill specialized data science positions |
Tip: Do not focus solely on base salary. PayPal’s equity and bonus structure often drive long term upside, especially as you move into senior or staff level roles.
Negotiation Tips That Work For PayPal
Negotiating at PayPal is most effective when you approach the conversation with clarity, professionalism, and strong evidence of market benchmarks. Recruiters appreciate candidates who understand both their value and how compensation components function across levels.
| Negotiation Tip | Why It Matters |
|---|---|
| Ask about level early | Your level (DS1, DS2, Senior, Staff) determines salary bands, bonus targets, and equity size. Even a one level shift can meaningfully increase total compensation. |
| Use multiple data sources | Referencing salary insights from Levels.fyi, Glassdoor, and Interview Query salaries helps you make specific, well supported requests anchored in real market data. |
| Leverage competing offers appropriately | PayPal recruiters expect data scientists to be interviewing across fintech, big tech, and AI companies. Sharing competing offers professionally helps align compensation expectations. |
| Highlight scope and impact | PayPal values quantifiable outcomes in fraud detection, risk modeling, and payment optimization. Leading with measurable impact strengthens your negotiation position. |
| Clarify location and hybrid expectations | Pay varies significantly across San Jose, San Francisco, New York, Austin, and remote roles. Understanding location based adjustments prevents surprises later in the process. |
Tip: Ask for a full compensation breakdown that includes base, bonus target, equity vesting, and any signing incentives so you can compare your offer against market benchmarks accurately.
FAQs
How long does the PayPal data scientist interview process take?
Most candidates complete the process within three to six weeks depending on team schedules and the number of technical rounds. Delays usually occur when multiple teams are considering your profile or if additional calibration is needed. Recruiters keep you updated throughout and will share timelines after each major step.
Does PayPal use HackerRank or online assessments?
Some teams use an initial online assessment for SQL or Python, especially for early career roles. Many mid level and senior candidates skip this step and move directly to technical screens. The format varies by team, but assessments generally focus on practical problem solving with structured datasets.
How important is payments or fraud experience for PayPal?
It is helpful but not mandatory. Candidates with strong analytical reasoning, machine learning background, or experimentation experience can ramp up quickly. Having exposure to risk modeling or transaction based data gives you an advantage, especially for teams working on fraud or trust and safety.
What is the difficulty level of PayPal’s SQL questions?
PayPal’s SQL questions tend to be moderately challenging and heavily scenario based. You can expect multi join queries, window functions, segmentation logic, and time based filtering. Many questions reflect real payment or fraud detection patterns, so clarity of reasoning matters as much as syntax.
Does PayPal allow candidates to choose teams after interviews?
Team matching usually happens after the onsite stage when the hiring committee approves your candidacy. Recruiters consider your interests, preferred work streams, and which teams have open headcount. Candidates often meet potential managers during this phase.
How technical are PayPal’s behavioral interviews?
Behavioral interviews focus on teamwork, communication, and how you handle ambiguity, but they often include light technical context. Interviewers may ask how you approached past projects, resolved conflicting data, or communicated model limitations. The goal is to understand how you collaborate across cross-functional environments.
What types of projects do PayPal data scientists typically work on?
Projects often involve fraud detection, risk scoring, payments optimization, experimentation, user behavior analysis, and merchant performance insights. Teams also work on building models for credit underwriting, dispute prediction, or checkout conversion. The scope varies widely depending on the product area.
Do senior data scientists face different interview expectations?
Yes, senior roles require deeper problem framing, stronger stakeholder management, and clear ownership of model strategy. Senior candidates are expected to articulate trade offs, lead ambiguous investigations, and influence decisions across teams. They often face additional rounds focused on leadership and long term thinking.
Does PayPal support remote or hybrid work for data science roles?
PayPal offers a mix of hybrid and remote options depending on the team and office location. Some roles require working onsite in hubs like San Jose, New York, or Austin, while others are fully remote. Recruiters typically specify location flexibility early in the process.
What metrics matter most in PayPal data science interviews?
Metrics often depend on the team, but common ones include authorization rate, fraud rate, dispute rate, chargeback frequency, conversion rate, and user verification success. You should understand how each metric affects user trust and merchant outcomes. Being able to connect metrics to product decisions is a strong differentiator.
How should I prepare for PayPal’s modeling interviews?
You should review feature engineering for transactional data, approaches for handling class imbalance, and techniques for monitoring drift. PayPal values practical explanations of model decisions over purely theoretical detail. Be ready to walk through end to end modeling workflows using examples from your past experience.
Is domain knowledge tested directly during interviews?
Interviewers may ask high level questions about payments flows, fraud patterns, or risk signals to see how well you understand real-world complexity. You are not expected to know every detail, but showing curiosity and basic intuition helps. Most domain knowledge can be learned on the job once your analytical foundation is strong.
Ready to Crack Your PayPal Data Scientist Interview?
Finishing the PayPal data scientist interview process is a meaningful accomplishment, and each stage gives you clearer insight into how data shapes trust, security, and product innovation across PayPal’s ecosystem. Whether you receive an offer or continue preparing, focus on strengthening your analytical rigor and product and risk intuition.
To keep building momentum, explore our full Interview Query question bank, level up with the Coaching Program, or simulate real interview pressure through Mock Interviews. With consistent practice, clear communication, and structured preparation, you will be well equipped for your next interview and ready to take on high impact data science challenges in fintech.