

Top 22 Meta Data Engineer Interview Questions + Guide in 2024

Introduction
Meta, formerly known as Facebook, is a leader in the social media landscape with a significant global presence. As of the third quarter of 2023, the platform boasts approximately 3.14 billion monthly active users, making it one of the world’s most popular social media networks.
This extensive user base presents a rich source of data, positioning Meta as a prime location for professionals in data science fields, including data engineering.
Data Engineers at Meta have the unique opportunity to work with advanced tools and technologies, contributing significantly to the company’s growth and enhancing user satisfaction.
Their role is pivotal in harnessing the vast data resources to generate actionable insights and drive business decisions.
If you’re considering applying for their data engineering role, then this guide is for you. By the end of this, you’ll have your hands full with Meta data engineer interview questions.
What is the Interview Process Like for a Data Engineering Role at Meta?
The interview process for a Data Engineering role at Meta consists of multiple stages that evaluate various skills, including technical proficiency, problem-solving ability, and cultural fit.
Here is a comprehensive overview of the process:
Initial Recruiter Phone Call
The Meta Data Engineering interview process begins with a phone call from a recruiter or HR representative. The call is an introduction to the role and the interview process, lasting around 30 minutes.
It is an important phase for assessing the candidate’s qualifications and suitability. Candidates can also gain information about the job details and what to expect in the next stages of the interview.
Technical Phone Screen
Candidates go through a technical phone interview after the initial screen. The interview lasts around one hour. The focus is on the candidate’s SQL and Python/Java coding skills.
Candidates are asked 8 to 10 questions using “Coderpad,” an online coding platform. The questions are evenly divided between SQL and Python/Java, including algorithmic challenges. The limited time of one hour requires efficient problem-solving and clear communication.
This round tests the candidate’s technical proficiency in a realistic coding environment.
Onsite Interview
The onsite interview, which may be conducted virtually, is a comprehensive and crucial part of the process, consisting of 3 to 4 interview rounds.
These include two ETL rounds focusing on SQL and Python/Java coding, a data modeling round where candidates are tested on their ability to design data models based on business scenarios, and a behavioral round. The ETL rounds simulate Meta’s standard ETL tasks, assessing the candidate’s skills in handling data engineering tasks.
The data modeling round evaluates the candidate’s ability to create efficient database schemas and data models. The behavioral round aims to understand the candidate’s communication skills, problem-solving abilities, and cultural fit within Meta.
During this stage, candidates are also given a chance to interact with Meta engineers informally, such as through a lunch break, offering insights into working at Meta.
Post-Interview Process
After interviews, the candidate’s performance is reviewed. Feedback is submitted and a meeting is held to discuss the hiring decision. This meeting includes a thorough review of the candidate’s performance, feedback, resume, and referrals.
The hiring committee, which includes senior leaders at Meta, makes the final decision. The committee usually follows the recommendation from the meeting and determines the job offer and compensation.

Meta Data Engineer Interview Questions
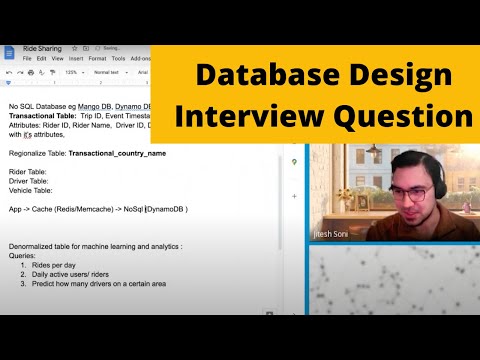
1. Design a ride-sharing schema.
Let’s say you work at a company developing a new ride-sharing app. How would you design a database that could record rides between riders and drivers? What would the schema of the tables look like, and how would they join together?
For a more comprehensive solution to the question, view the following video for a full mock interview in designing a ride-sharing schema:
2. Design a Parking System.
Suppose that you are tasked in designing a parking system for a busy urban area. This is a smart parking system allowing for automated slotting of parking slots via a mobile app. Here are the functional requirements
Real-Time Space Occupancy Tracking:
The parking system must continuously monitor and update the status of each parking space, indicating whether it’s occupied or available. This real-time tracking should be accurately reflected in the system at all times.
Integrated Booking and Cost Management via App:
The system should enable users to automatically reserve parking spaces through a mobile app. Additionally, this app should manage the cost of parking dynamically, updating the pricing in real-time based on various factors like demand, duration of parking, and vehicle type.
Analytics System Support:
The parking system should be capable of supporting an analytics platform. This platform would analyze data such as occupancy patterns, peak usage times, and revenue generation, thereby providing insights for optimizing operations and future planning.
Advanced Booking Capabilities:
Users should have the ability to book parking spaces in advance through the system. This feature would allow for better planning, especially during peak hours or for events, and could potentially integrate with a cancellation or penalty system for no-shows.
Dynamic Pricing on Initial Booking:
Implement a dynamic pricing model that determines the cost of parking at the time of the initial booking. This pricing should be influenced by factors such as the time of booking, anticipated demand at the parking time, and the type of vehicle. The price set at booking should remain fixed for that particular reservation.
3. How can you merge two sorted lists?
Given two sorted lists, write a function to merge them into one sorted list. For example:
list1 = [1,2,5]
list2 = [2,4,6]
The output would be:
def merge_list(list1,list2) -> [1,2,2,4,5,6]
As a bonus, can you determine the time complexity of your solution?
4. Can you describe how an operating system manages memory?
In many programming languages, there are explicit keywords that indicate that you are using memory. For example, in more esoteric low-level system languages like C and C++, you can declare memory using explicit memory allocation functions such as **malloc()**. However, in newer languages, the new keyword is more commonplace (even in C++, although it’s a deprecated manner of instantiating objects). In languages like Python, however, they can be more nuanced, such as treating classes as callable (i.e., class() ) or through the use of [], {}, ().
However, not all memory is treated the same. Can you describe:
- What is heap versus stack memory?
- Which memory storage is faster?
- In most languages, why is the heap used for bigger memory structures (i.e., objects)?
- In languages like Python, why is almost everything in the heap? As a rule of thumb, what types of data are stored in the heap, and what types are stored in the stack?
5. How can you implement Dijkstra’s algorithm in Python?
Implement Dijkstra’s shortest path algorithm for a given graph with a known source node. A graph format is a dictionary of nodes as key and the value is a dictionary of neighbors to that node with the distance between them as follows.
6. Can you create a sub-O(n) search algorithm for a pivoted array?
Suppose an array sorted in ascending order is rotated at some pivot unknown to you beforehand.
You are given a target value to search. If the value is in the array, then return its index; otherwise, return -1.
Notes:
- Rotating an array at pivot $n$ gives you a new array that begins with the elements after position $n$ and ends with the elements up to position N.
- You may assume no duplicate exists in the array.
Bonus: Your algorithm’s runtime complexity should be in the order of O(log\;n).
7. Write a SQL query to output the average number of right swipes for two different variants of a feed ranking algorithm by comparing users that have swiped 10, 50, and 100 swipes in a feed_change experiment.
There are two tables. One table is called swipes that holds a row for every Tinder swipe and contains a boolean column that determines if the swipe was a right or left swipe called is_right_swipe. The second is a table named variants that determines which user has which variant of an AB test.
Write a SQL query to output the average number of right swipes for two different variants of a feed ranking algorithm by comparing users that have swiped 10, 50, and 100 swipes in a feed_change experiment.
Note: Users have to have swiped at least 10 times to be included in the subset of users to analyze the mean number of right swipes.
8. Calculate the first touch attribution for each user_id that converted.
The schema below is for a retail online shopping company consisting of two tables, attribution and user_sessions.
- The attribution table logs a session visit for each row.
- If
conversionistrue, then the user converted to buying on that session. - The
channelcolumn represents which advertising platform the user was attributed to for that specific session. - Lastly the
user_sessionstable maps many to one session visits back to one user.
First touch attribution is defined as the channel with which the converted user was associated when they first discovered the website.
Calculate the first touch attribution for each user_id that converted.
9. Use the window function RANK to display the top three users by downloads each day.
Let’s say you work at a file-hosting website. You have information on the user’s daily downloads in the download_facts table
Use the window function RANK to display the top three users by downloads each day. Order your data by date, and then by daily_rank.
10. Write a query to determine the top 5 actions performed during the month of November 2020, for actions performed on an Apple platform (iPhone, iPad).
The events table tracks every time a user performs a certain action (like post_enter, etc.) on a platform (android, web, etc.).
The output should include the action performed and it’s rank in ascending order. If two actions are performed equally, they should have the same rank.
11. What are the fundamentals of building a data pipeline?
The fundamentals of building a data pipeline include:
- Data Collection: Gathering data from various sources, such as databases, files, external APIs, or streaming sources.
- Data Processing: Transforming and manipulating the data to fit the desired format or structure. This may involve filtering, sorting, aggregating, or enriching the data.
- Data Storage: Choosing appropriate storage solutions to keep the processed data. This could be in databases, data lakes, or data warehouses, depending on the use case.
- Data Orchestration: Managing the workflow of data through various stages of the pipeline. This involves scheduling tasks, managing dependencies, and ensuring efficient and error-free data flow.
- Monitoring and Logging: Implementing mechanisms to track the performance of the pipeline, detect errors, and log activities for auditing and debugging purposes.
- Scalability and Performance: Ensuring that the pipeline can handle growing data volumes and complex processing requirements without performance degradation.
- Data Security and Compliance: Applying security measures to protect data and comply with regulations like GDPR, HIPAA, etc.
- Testing, Quality Assurance and Documentation: Regularly testing the pipeline to ensure data quality and pipeline reliability. Keeping clear documentation is also important for future reference and maintaining the pipeline to adapt to new requirements or changes in data sources.
12. Given a string, write a function recurring_char to find its first recurring character.
Given a string, write a function recurring_char to find its first recurring character. Return None if there is no recurring character.
Treat upper and lower case letters as distinct characters.
You may assume the input string includes no spaces.
13. When should you consider streaming over batching?
Streaming is preferable over batching in scenarios that demand real-time data processing, especially when dealing with continuous data sources like IoT devices. It’s ideal for situations requiring low latency, as data is processed instantly upon arrival. Streaming also suits applications needing frequent updates, like live dashboards. In terms of resource efficiency, streaming handles smaller data chunks continuously, which can be more manageable than the intensive resource requirements of batch processing.
14. In the ethics of web scraping, what file or resource in the source website should you always consult prior to allowing scraping?
In ethical web scraping practices, the robots.txt file of a website is a critical resource to consult. This file is designed to guide and restrict the activities of web crawlers and scrapers, indicating which parts of the site should not be accessed. Adhering to the directives specified in robots.txt is a fundamental aspect of responsible and ethical web scraping.
15. Implement a priority queue using a linked list in Python.
Priority queues are an abstract data structure responsible for allowing enqueuing items with an attached priority. While typically implemented with a heap, implement a priority queue using a linked list.
The Priority Queue implementation should support the following operations:
insert(element, priority): This operation should be able to insert an element into the Priority Queue, along with its corresponding priority.delete(): This operation should remove and return the element with the highest priority. If multiple elements share the same highest priority, the element first enqueued should be returned. In the case that the queue is empty, return None.peek(): This operation should return the element with the highest priority without removing it from the Priority Queue. Again, in the case of equal highest priorities, the element first enqueued should be returned. In the case that the queue is empty, return None.
Note: Smaller priority values imply that they have higher priority.
16. How would you build an ETL pipeline for Stripe payment data?
More context. Let’s say that you’re in charge of getting payment data into your internal data warehouse.
How would you build an ETL pipeline to get Stripe payment data into the database so that analysts can build revenue dashboards and run analytics?

17. What are the considerations when using stored procedures?
Using stored procedures in database management systems involves weighing both their advantages and disadvantages. On the positive side, stored procedures can significantly enhance performance. They execute within the database server, which minimizes the amount of data sent over the network. This is particularly beneficial for complex queries, as it reduces the overhead associated with parsing and executing SQL statements transmitted from a client application. Stored procedures also offer advantages in terms of security, as they provide a layer of abstraction between the data and the application layer, allowing for more controlled data access.
However, there are notable downsides to using stored procedures. One major concern is their non-portability. Since stored procedures are often specific to a particular database system, moving an application to a different database can require significant rework of these procedures. Another critical challenge is testing and debugging. Stored procedures can be difficult to debug, particularly because they run on the database server, often requiring different tools and techniques compared to regular application debugging. The integration of stored procedures with version control systems can also be less straightforward, potentially complicating development workflows.
Moreover, while stored procedures can improve performance by reducing network traffic, they can also lead to performance bottlenecks if not written efficiently. As the business logic becomes more complex, the maintenance of these procedures can become cumbersome, potentially leading to issues with maintainability and scalability.
Despite these challenges, stored procedures offer a centralized way to manage business logic within the database, which can simplify some aspects of application development and maintenance. They also provide a mechanism for reusing code and encapsulating logic, which can lead to cleaner, more organized codebases. When used judiciously, stored procedures can be a powerful tool in the arsenal of a database administrator or developer, but it’s important to be mindful of their limitations and use them appropriately.
18. When querying data from a SQL database for an ETL process, you noticed that the entire result set is larger than your computer’s memory. How will you solve this problem?
When working with Big Data, it is common to encounter data sets larger than our machine’s memory. You might even be working with datasets that are double or triple your computer’s memory. The key here is to remember that we don’t have to pull all the data in one go, especially when there are robust tools designed to handle such scenarios. Enter the age-old solution: streaming.
When dealing with large datasets, it is better to use streaming in order to chunk-down your dataset into manageable pieces. Big Data frameworks such as Hadoop and Spark can help you streamline this process.
- Apache Hadoop: A well-known software framework for distributed storage and processing of large datasets. Hadoop’s HDFS (Hadoop Distributed File System) can store enormous amounts of data, and its MapReduce component can process such data in parallel.
- Apache Spark: A powerful tool for big data processing and analytics. Spark excels in handling batch processing and stream processing, with Spark SQL allowing you to execute SQL queries on massive datasets.
- Apache Beam: Beam is a unified model for defining both batch and streaming data-parallel processing pipelines. It provides a portable API layer for building sophisticated data processing pipelines that can run on any execution engine.
- Apache Flink: Known for its speed and resilience, Flink is excellent for stream processing. It’s designed to run stateful computations over unbounded and bounded data streams.
Aside from these Big Data frameworks, you can still adopt the traditional approach of fetching and processing data in smaller batches. SQL query optimizations using LIMIT and OFFSET clauses can help you retrieve a portion of the records, allowing you to iterate through your data in manageable chunks instead of trying to load everything into memory all at once.
19. How would you handle rapidly growing SQL tables?
More context. Consider a SQL database where the table logging user activity grows very rapidly. Over time, the table becomes so large that it begins to negatively impact the performance of the queries. How would you handle this scenario in the context of ETL and data warehousing?
To handle rapidly growing SQL tables in the context of ETL and data warehousing, you can employ several strategies to improve performance. For example, partitioning is a technique that involves dividing the large table into smaller partitions based on a specified criterion. Another helpful strategy is indexing, which allows queries to run faster, reducing execution time.
Archiving, or purging, older data that is no longer actively used for reporting or analysis can also help manage the table size. Moving these older records to an archival database or storage system reduces the data processed during queries, leading to improved performance.
For analytics and reporting, the use of summary tables, OLAP cubes, and data warehousing can help reduce the query times. As a last resort, scaling up or scaling out the database infrastructure can accommodate the growing load. Scaling up involves upgrading hardware resources, while scaling out involves distributing the load across multiple servers or utilizing sharding techniques
20. How do you manage pipelines involving a real-time dynamically changing schema and active data modifications?
Dynamically changing schemas are troublesome and can create problems for an ETL developer. Changes in the schema, data, or transformation modules are both high-cost and high-risk, especially when you are dealing with massive databases or when the wrong approach is pursued.
How then do you manage pipelines involving a changing schema and active data modifications? Such a question is relatively easy to phrase but is challenging to visualize correctly. It is helpful to visualize the problem with an example:
- You have two databases, one of which will handle raw data and be appropriately named
RAW. - The data in the
RAWdatabase needs to be transformed through some code, most often Python. This process can include the cleaning, validation, and pushing of said processed data into our second database, which we will nameOUT. OUTis the database designed to collate all processed data from RAW. Data fromOUTwill be prepared and transported to an SQL database.- There are possible changes in the
RAWdatabase, including schema changes, such as the changing of values, attributes, formats, and adding or reducing fields. - Your problem is that you will need the
RAWandOUTdatabase to be consistent whenever a change occurs.
There are many ways to approach this problem, one of which is through CI/CD. CI/CD stands for continuous implementation and continuous development.
Knowing that changing or modifying anything in the RAW database can make or break a whole ecosystem of data, it is imperative to use processes that come with many safety measures and are not too bold during implementation. CI/CD allows you to observe your changes and see how the changes in the RAW database affect the OUT database. Typically, small increments of code are pushed out into a build server, within which exist automated checking areas that scan the parameters and changes of the released code.
After the checks, the ETL developer will look at the feedback and sift through the test cases, evaluating whether the small increment succeeded or failed. This process allows you to check how the changes in the RAW database affect those in the OUT database. Because the changes are incremental, they will rarely be catastrophic if they do evade your checks and negatively impact the database, as they will be easily reversible.
Typically, after raw data goes through the transformation pipeline, there will be metadata left which can include a hash of the source in RAW, the dates and time it was processed, and even the version of code you are using.
After that, use an orchestrator script that checks for new data added to the RAW database. The orchestrator script can also check for any modifications made to the RAW database, including additions and reductions. The script then gives a list of updates to the transformation pipeline, which processes the changes iteratively (remember: CI/CD).
21. Write a function to find how many friends each person has.
You are given a list of lists where each group represents a friendship. Person 2 is friends with person 3, person 3 is friends with person 4, etc.
22. Write a query to create a metric to recommend pages for each user.
Let’s say we want to build a naive recommender. We’re given two tables, one table called friends with a user_id and friend_id columns representing each user’s friends, and another table called page_likes with a user_id and a page_id representing the page each user liked.
Note: It shouldn’t recommend pages that the user already likes.
How to Prepare for a Data Engineering Role at Meta
Let’s go through some tips that can help you ace Meta data engineer interview questions
Understanding Meta’s Data Ecosystem
To succeed in a data engineering role at Meta, you must understand their complex data ecosystem. This involves being skilled in big data technologies like Apache Hadoop, Spark, and Kafka, which are used for managing large-scale data processes.
You should also be aware of the data challenges and opportunities unique to Meta, such as using data to enhance user engagement and drive business growth. Having a thorough understanding of how data is utilized within Meta’s framework will give you an important edge.
Utilize our Company Interview Guides. This page offers in-depth research and data on not just Meta’s but also from other companies such as Airbnb, Amazon, Google, and so much more, helping you understand the specific technologies and platforms used at Meta.
Proficiency in Relevant Programming Languages
A successful career at Meta requires strong skills in SQL, Python, and Java, as these languages are heavily used in data engineering tasks. During the interview process, your ability to write efficient, clean, and well-documented code will be rigorously assessed.
Therefore, it is important to concentrate on improving your coding skills in these languages, with an emphasis on writing code that is both functional and easy to maintain.
Consider checking out our Challenges. This section allows you to test your coding skills against others, giving you a sense of where you stand and areas for improvement.
Mastering Data Modeling and Database Design
A strong knowledge of data modeling and database design is necessary for a data engineer at Meta. This includes understanding relational and non-relational databases, mastering data normalization principles, and understanding data warehousing.
You should be prepared to demonstrate your abilities in designing database schemas and optimizing queries for better performance, as these are typical tasks in this role.
Our Takehomes offer practical exercises that mimic the data modeling and database design challenges you might face at Meta. These exercises provide step-by-step problems similar to those in real-world scenarios, allowing you to practice designing database schemas and optimizing queries, which are critical skills for Meta’s data engineering role.
Building Skills in Data Pipeline Design and ETL Processes
It is important to develop expertise in designing data pipelines and ETL processes. This involves understanding efficient data movement and transformation techniques. Being familiar with data pipeline orchestration tools, like Apache Airflow, can greatly improve your profile. Showing that you can build and manage efficient, reliable data pipelines will be a crucial part of your role at Meta.
For honing your skills in data pipeline design and ETL processes, our Data Science learning path can be particularly useful. This course covers a wide range of topics relevant to this area, so do consider checking it out.
Experience with Data Visualization and Reporting Tools
Gaining experience in data visualization and reporting is important. Tools like Tableau and Excel are commonly used to present data insights in a accessible way. Being skilled at creating informative dashboards and reports is necessary, as these skills help communicate complex data findings effectively, supporting the company’s decision-making processes.
To gain proficiency in data visualization and reporting tools like Tableau and Excel, consider exploring our Data Analytics course.
Staying Updated with Big Data Solutions and Technologies
Staying informed about the latest trends in big data solutions and technologies is important in a rapidly evolving field. It is essential to be familiar with technologies like Spark and EME due to their frequent use in high-scale data processing at Meta.
Showing a continuous dedication to learning and adapting to the latest technologies will demonstrate your potential to make significant contributions to Meta’s data engineering challenges.
Check out our blog. This section provides recent articles and guides on data science careers and interviewing, ensuring you stay informed about technologies related to Meta’s data engineering role.
Practicing Real-World Problem Solving
Engaging in practical exercises that mimic real-world data challenges is vital. This means not only being proficient in writing complex SQL queries but also optimizing database performance and designing data models for real business cases. Utilizing platforms like Interview Query to practice can provide a realistic sense of the problems faced in a data engineering role at Meta, preparing you for the kinds of scenarios you might encounter.
To effectively practice real-world problem-solving, explore our ‘Interview Questions’ section. Here, you’ll find a diverse array of data science and machine learning questions used by leading tech companies, so try reading some of our posts.
Preparing for Behavioral and Communication Skills Assessment
Meta values both technical expertise and cultural fit, as well as communication skills. During the interview process, be prepared to discuss your experiences in problem-solving, collaboration, and overcoming challenges. It is important to effectively and clearly communicate your thought process, as well as provide technical solutions.
To prepare for the behavioral and communication aspects of Meta’s interview process, consider using our Mock Interviews. This service allows you to initiate mock interview sessions, providing a platform to practice and receive feedback on your communication and problem-solving skills in a simulated interview environment.
Whiteboard Coding Practice
Becoming familiar with whiteboarding is necessary for Meta’s interview process because it is commonly used. It is important to practice coding on a whiteboard or by hand, emphasizing accuracy and clarity without relying on an IDE. The ability to explain your code and thought process simultaneously is a valuable skill in interviews.
Enhance your whiteboarding skills with our Coaching service. Here, you can receive expert help from professionals at top tech companies, including guidance on whiteboarding techniques and articulating your thought process during coding challenges.
Understanding Meta’s Business and Product Philosophy
Finally, it is important to have a thorough understanding of Meta’s products, business model, and the role data plays in achieving the company’s goals.
Demonstrating how your skills and expertise can contribute to Meta’s vision will make a difference as a candidate. Be ready to discuss how your role as a data engineer can align with and improve Meta’s products and services.
To deepen your understanding of Meta’s business and product philosophy, engage with our “Leaderboard” and “Slack community.”
These allow you to interact with data scientists, engineers, and product managers, giving you insights into the latest trends and discussions in the tech community, which can be helpful in aligning your preparation with Meta’s values and expectations.
FAQs
Here is information on both Interview Query’s resources and Meta’s data engineering interview guide:
What is the typical salary for a Data Engineer at Meta?
Average Base Salary
Average Total Compensation
The typical salary for a Data Engineer at Meta is approximately $162,744 as a base salary, with an average total compensation of around $216,426 when including additional components like bonuses and stock options.
This information is based on a certain number of self-reported data points and may vary depending on individual circumstances such as experience, location, and specific role within the company.
Is there a platform on Interview Query for discussions about the Data Engineering role at Meta?
No, we don’t have any discussion posts specifically about Meta’s data engineering position. However, you can read through our discussion board to see all the positions and companies that we cover here at Interview Query.
Does Interview Query list job openings for Data Engineering positions at Meta?
Yes, we currently have open data engineering positions. You can check them out through our ‘Data Engineer at Meta Jobs’ section.
Conclusion
Each of these areas contributes to a well-rounded preparation strategy for aspiring Data Engineers looking to join Meta.
If you need more information, consider checking out our main Meta Interview Guide. We’ve prepared interview questions for different roles, such as their data analyst, scientist, machine learning engineer, software engineer, business analyst, and intelligence, among others.
Also, consider our other guides where we cover Data Engineer guides, such as our main Data Engineering interview questions, Python questions, and case studies.
By focusing on these key aspects, you can build a profile that not only showcases your technical abilities but also aligns with Meta’s unique business needs and culture.
We hope that you’ve learned something today, and we look forward to your success in your data engineer interview at Meta.
Onward and forward!