

Meta ML Engineer Interview Decoded 2025: Systems, Strategy, Success


Introduction
If you want to join the team shaping the future of AI at global scale, Meta is where ideas become intelligent systems that reach billions. Its machine learning engineers design the models behind personalized feeds, generative AI tools, and recommendations that power Facebook, Instagram, and WhatsApp.
Preparing for a Meta machine learning engineer interview means proving more than technical skill. You must show how you think about data, make trade-offs, and turn models into real impact. This Meta ML interview guide walks you through every interview stage, explains what interviewers value, and helps you showcase your strengths with precision and confidence.
Role overview and culture
As a machine learning engineer at Meta, you’ll work at the intersection of data science, software engineering, and applied research. Your day-to-day tasks include building large-scale models, optimizing pipelines, and integrating systems that power everything from content recommendations to safety filters and generative AI tools.
Meta’s culture rewards engineers who can combine experimentation with impact. You’ll often be expected to take ownership of entire problem spaces, from designing model architectures to evaluating their downstream effects. Collaboration is key; ML engineers work closely with data scientists, product managers, and infrastructure teams to ship models that not only perform well in testing but scale reliably in production.
A defining trait of Meta’s engineering culture is its bias toward rapid iteration. You’re encouraged to experiment, measure, and improve continuously rather than over-engineer a perfect solution. This approach means being comfortable with ambiguity, prioritizing metrics that drive user value, and communicating results clearly across teams.
Why this role at Meta
Machine learning at Meta operates at a scale few companies can match. Models process trillions of events every day, shaping feeds, recommendations, and integrity systems in real time. One example is Meta’s internal platform Looper, which allows engineers to deploy optimization and personalization models quickly across products while learning from billions of user interactions. As an ML engineer, you will design distributed systems that train on massive datasets, serve predictions at low latency, and influence how people connect and share globally.
The role is also defined by visible impact. Meta’s fast-moving environment means your work can go live within days or weeks. Whether you are improving a ranking model to enhance engagement or developing fairness-aware systems to ensure inclusion, you will link algorithmic rigor with tangible outcomes. In your interviews, focus on examples where your technical decisions led to measurable improvements in performance, efficiency, or user experience.
Meta ML Engineer Interview Process
The Meta ML interview process is designed to find people who can turn raw data into scalable systems that shape real user experiences. The process looks beyond algorithms and syntax. It tests how you think, how you structure problems, and how you explain your reasoning clearly under time pressure.
The entire process usually spans three to five stages. Each one focuses on a different dimension of what it means to build and deploy machine learning at scale.
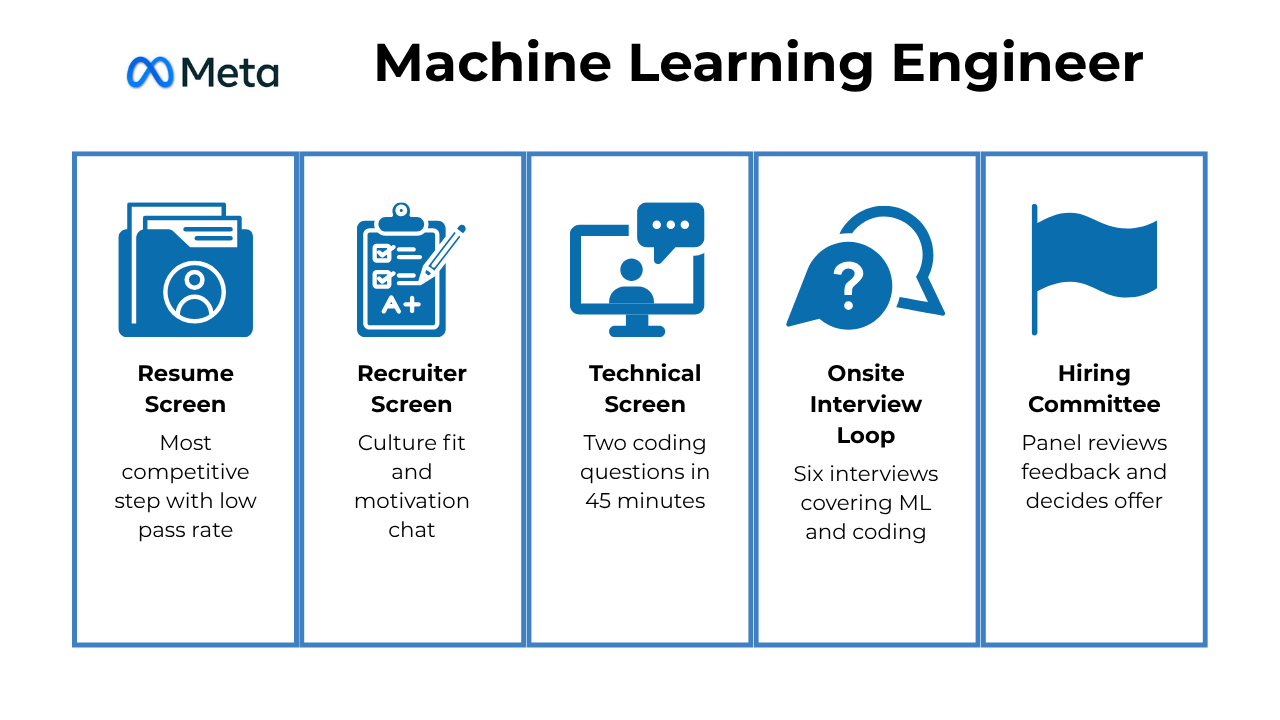
Recruiter screen
Your first conversation with Meta is a short call with a recruiter. This stage lasts about 30 minutes and helps the team understand your background, technical depth, and what excites you about machine learning at Meta. You can expect questions about your most impactful projects, the kinds of models you have built, and the tools or frameworks you use daily.
Recruiters also clarify the structure of the next interviews, explain which teams you might align with, and ensure your skills match Meta’s needs.
Tip: Approach this call like a product pitch about yourself. Highlight one or two projects that show measurable impact. For example, “I built a recommendation model that improved click-through rate by 15 percent across a 10-million-user dataset.” Specific results make you memorable.
Technical screening
If you move forward, you will take part in one or two virtual technical interviews. These sessions combine algorithmic problem solving with practical ML reasoning. The first part often focuses on core computer science topics like arrays, graphs, or recursion. The second part introduces ML-specific scenarios that test your understanding of data pipelines, model evaluation, or feature engineering.
Interviewers want to see how you approach ambiguity. For example, you might be asked to process millions of events in real time, then explain how you would scale the logic for production. They are not only judging your accuracy but also how well you communicate your decisions.
Tip: Think aloud as you code. Walk the interviewer through your logic before you start typing. Clear explanations under pressure show confidence and collaboration.
Test your skills with real-world analytics challenges from top companies on Interview Query. Great for sharpening your problem-solving before interviews.
Virtual or on-site interview loop
This is the heart of the interview process. The full loop usually includes four or five interviews that test a balance of technical skill, applied reasoning, and communication. You may complete them virtually or in person.
Coding interview
This session focuses on data structures and algorithms. You might be asked to design an efficient search algorithm, process streaming data, or debug a complex function. The goal is to see how well you write clean, efficient, and correct code under pressure.
Tip: Start with a clear plan. Briefly explain your approach before coding, and check for edge cases once you finish. Interviewers want to see how you think through problems end to end.
ML system design interview
This is one of the most challenging rounds. You will be asked to design an end-to-end ML pipeline for a real problem, such as ranking feed posts or detecting fraud. Discuss the data sources you would use, feature engineering, model selection, evaluation metrics, deployment flow, and monitoring. The interviewer will push you to think about scale, latency, and trade-offs.
Tip: Balance technical rigor with practicality. It is better to explain a simple, scalable approach clearly than to describe a complicated design you cannot justify.
Applied modeling interview
Here you will demonstrate how you handle realistic modeling challenges. Expect questions about model drift, missing data, class imbalance, or experimentation. You might be asked to analyze why a model is underperforming and suggest improvements.
Tip: Focus on iteration. Talk about how you would diagnose performance issues and improve over time. Interviewers want to see that you understand machine learning as an ongoing process, not a one-time project.
Behavioral interview
This round examines how you work with others. Interviewers look for ownership, curiosity, and a growth mindset. You may be asked to describe a difficult project, how you resolved team conflicts, or how you handled feedback.
Tip: Use the STAR method: Situation, Task, Action, Result. Keep your stories concise and emphasize what you learned. Meta appreciates candidates who are reflective and outcome-oriented.
Hiring committee and offer process
After your interviews, each interviewer writes detailed feedback about your performance. A hiring committee then reviews these notes collectively, looking for consistent strengths in four areas: technical skill, problem-solving ability, communication, and cultural fit. The committee’s goal is to ensure fairness and alignment with Meta’s engineering standards.
If approved, you will enter the team matching stage. This is where Meta helps you connect with specific teams whose missions match your interests. You will meet potential managers, learn about their ongoing projects, and decide which environment best fits your goals. Only after this stage is complete does the recruiter move into offer discussions that include compensation, equity, and start date.
The entire process can take several weeks, depending on scheduling and team availability.
Tip: Treat the team matching process as an extension of your interview. Come prepared with thoughtful questions about the team’s challenges, data scale, and long-term priorities. Showing genuine curiosity about where you fit makes a strong final impression.
What Questions Are Asked In A Meta Machine Learning Engineer Interview?
Meta ML interview questions are designed to test how you think, not just what you know. You’ll need to demonstrate strong technical depth, problem-solving clarity, and the ability to explain machine learning concepts in practical, production-oriented terms.
While the questions vary by team, most interviews include a balance of coding, theoretical ML knowledge, and applied design. You should be ready to show how you evaluate trade-offs, reason through data challenges, and connect models to real business outcomes.
Coding interview questions
Coding questions assess how well you can write efficient, maintainable, and scalable code. You’ll be expected to explain your logic as you work through problems and to think beyond correctness by discussing complexity, trade-offs, and design considerations.
-
This SQL question measures your ability to summarize and compare large datasets efficiently. Start by describing how you’d group departments, filter those meeting the minimum size, and calculate the share of employees earning above the threshold. Explain how you’d rank results and ensure accuracy with tie values or missing data. At Meta, understanding how to handle scale and optimize queries for billions of records is critical.
Tip: Talk about using indexes, temporary tables, or precomputed aggregates to improve performance when working with massive datasets.
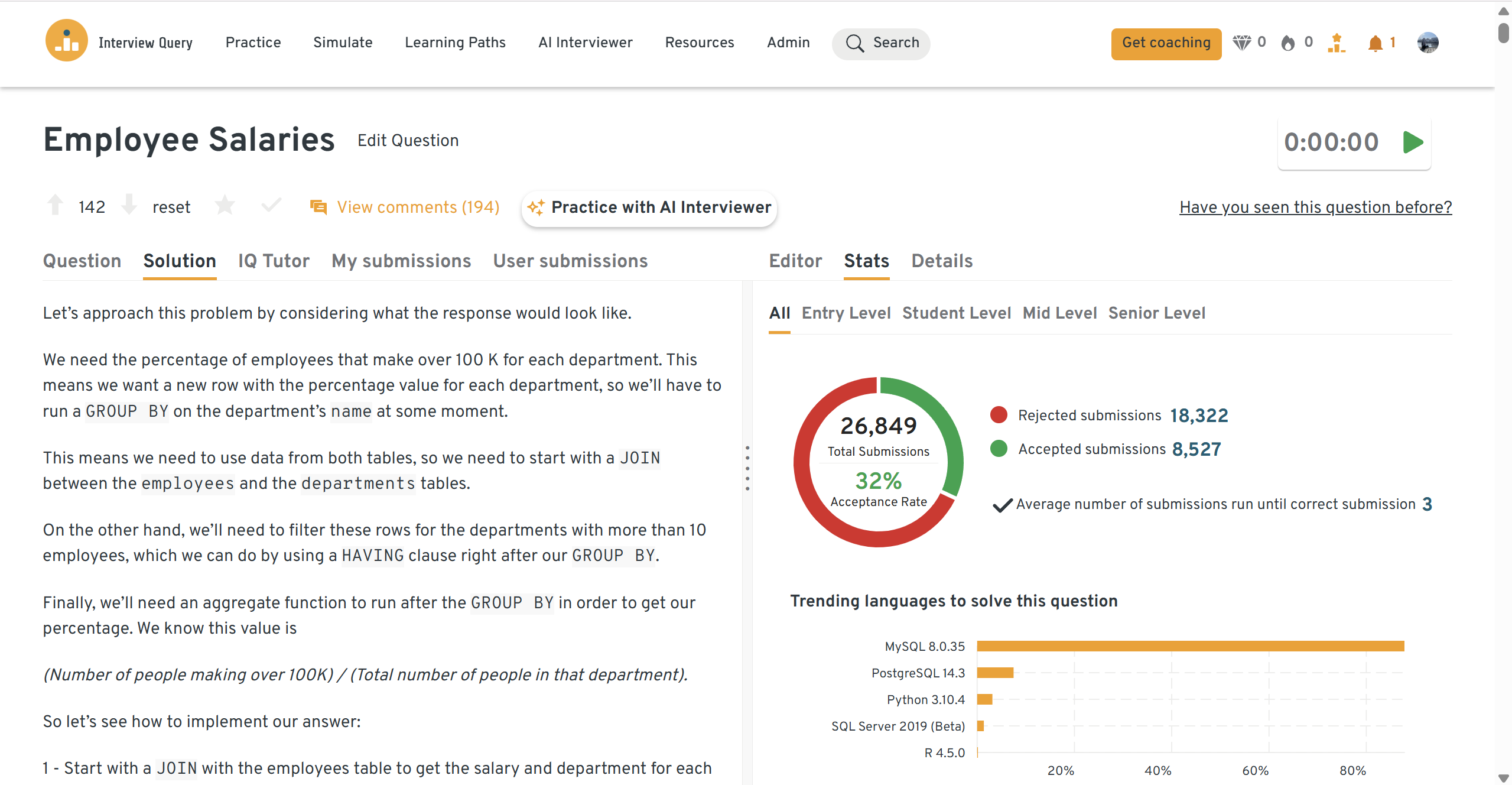
You can practice this exact problem on the Interview Query dashboard, shown below. The platform lets you write and test SQL queries, view accepted solutions, and compare your performance with thousands of other learners. Features like AI coaching, submission stats, and language breakdowns help you identify areas to improve and prepare more effectively for data interviews at scale.
How would you write a query to return only the duplicate rows in a users table?
This question evaluates how you approach data quality, which is foundational for reliable model training. Explain how you’d group by key identifiers, count occurrences, and filter where the count exceeds one. Extend your answer to describe how you’d prevent duplicates through constraints or validation checks.
Tip: Show initiative by suggesting a pipeline approach. For example, scheduling automated deduplication checks before data reaches the training phase.
-
This algorithmic problem tests coding fluency and efficiency. Explain how you’d use two pointers to traverse both lists in linear time while maintaining sorted order. Address special cases like uneven or empty lists. For machine learning engineers, link this to combining sorted prediction outputs or merging ranked datasets in production systems.
Tip: After writing your code, clearly state your time and space complexity. Meta interviewers value concise reasoning supported by technical clarity.
How would you calculate the new median when inserting a number into a running data stream?
This question assesses your understanding of real-time computation, which is crucial for large-scale model serving. Describe how you’d use two heaps to maintain the lower and upper halves of the data, ensuring they stay balanced after every insertion. Then explain how this allows you to retrieve the median efficiently without re-sorting the entire dataset.
Tip: Connect your explanation to real-world systems, such as maintaining rolling statistics in recommendation pipelines where latency is key.
Is there a path from a starting cell to a target cell in a maze?
This problem tests how you design algorithms that explore state spaces efficiently. Explain how you’d represent the maze as a grid or graph and use breadth-first search (BFS) to check for connectivity. Mention how you’d manage visited cells, handle walls, and ensure you don’t revisit nodes unnecessarily.
Tip: Walk the interviewer through your reasoning aloud. Clear communication while coding demonstrates both competence and collaboration, traits Meta values highly.
Machine learning fundamentals interview questions
Machine learning fundamentals questions appear mainly in machine learning engineer interviews. These questions test your grasp of core ML principles, how different algorithms behave, and how to evaluate or improve them. While AI engineers might see a few of these, they are usually tested more on applied reasoning than on the mathematical or theoretical depth of model training.
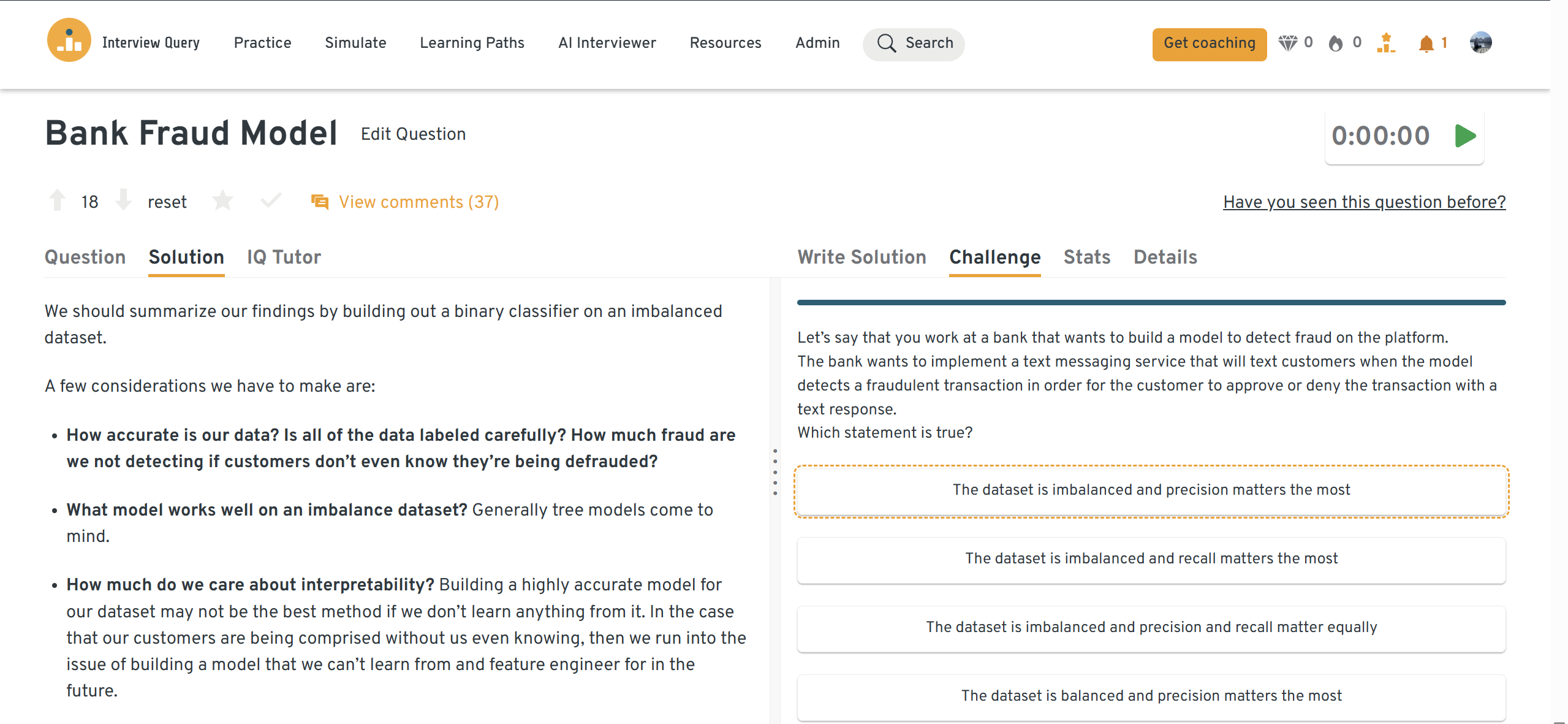
How would you build a model to detect bank fraud and design a text-alert system around it?
This question evaluates how you think about designing a full end-to-end ML pipeline. Start by describing the data you would collect, such as transaction history, user demographics, merchant information, and time-based behavior patterns. Explain how you would define fraud, create labels, and perform feature engineering to capture key signals like transaction frequency or location anomalies.
Next, discuss model selection. You could compare approaches like logistic regression for interpretability versus gradient boosting for complex decision boundaries. Clarify how you would monitor metrics such as precision, recall, and false-positive rate. Finally, outline how the text-alert system becomes part of the feedback loop. Customer responses provide valuable labels that help retrain and improve the model over time.
Tip: Show that you understand trade-offs. Catching more fraud is valuable, but alerting users too often damages trust. Meta interviewers want to see that you balance model performance with user experience.
-
This question tests your understanding of model behavior and assumptions. Start by explaining that linear regression assumes linear relationships and works best with well-scaled, low-noise data. Random forest regression, in contrast, captures nonlinear interactions and handles outliers more effectively.
Walk through how you would evaluate both approaches using cross-validation and error metrics such as RMSE or MAE. Emphasize that model performance depends on data complexity, feature distribution, and interpretability needs.
Tip: Meta interviewers look for analytical reasoning rather than one right answer. Explain how you would experiment with both models, validate results, and make the decision based on evidence rather than intuition.
How does random forest generate the forest, and why would we use it over logistic regression?
This question checks your conceptual foundation. Explain how random forest creates multiple decision trees using bootstrapped samples and random feature subsets, then aggregates results to reduce variance. Compare it to logistic regression, which models linear relationships and works well for simpler, interpretable problems.
Discuss situations where random forest performs better, such as high-dimensional data or nonlinear relationships, but also acknowledge its higher computational cost.
Tip: Relate your answer to real projects. For example, say you would use logistic regression for quick baselines but switch to random forest once you detect nonlinear dependencies in the data.
How would you build the recommendation algorithm for type-ahead search for Netflix?
This question focuses on personalization and ranking under time constraints. Explain that you would combine query embeddings, user behavior, and collaborative filtering to generate relevant suggestions as the user types. Discuss how you would rank results by probability of engagement and handle latency challenges through caching or approximate nearest neighbor search.
Finally, describe how you would measure performance using click-through rate, recall at K, or dwell time.
Tip: Show awareness of scale. Meta’s search and recommendation models serve billions of queries, so emphasizing efficient indexing, distributed serving, and low-latency inference demonstrates maturity.
-
This question tests how you balance user engagement with responsible content distribution. Start by outlining potential features, such as engagement history, social proximity, content type, and posting recency. Describe how you would train a ranking model using supervised signals like clicks, shares, or watch time.
Next, explain how you would optimize for diversity by tuning the ratio of public and private content to prevent filter bubbles. Discuss key metrics like engagement rate, session time, and content diversity scores.
Tip: Always connect technical decisions to user experience. Meta interviewers want to see that you understand how algorithmic choices shape what people see and how they feel when using the product.
System design interview questions
System design questions in Meta’s machine learning engineer interviews assess how well you can architect scalable ML solutions from end to end. You’ll need to demonstrate technical depth, design intuition, and the ability to reason about trade-offs in data pipelines, model serving, and real-time systems.
While software engineers may focus on distributed systems or infrastructure scalability, ML engineers must show how data flows through training, inference, and monitoring. You are expected to connect the dots between algorithms and production constraints, balancing performance, latency, and ethical considerations like fairness and safety.
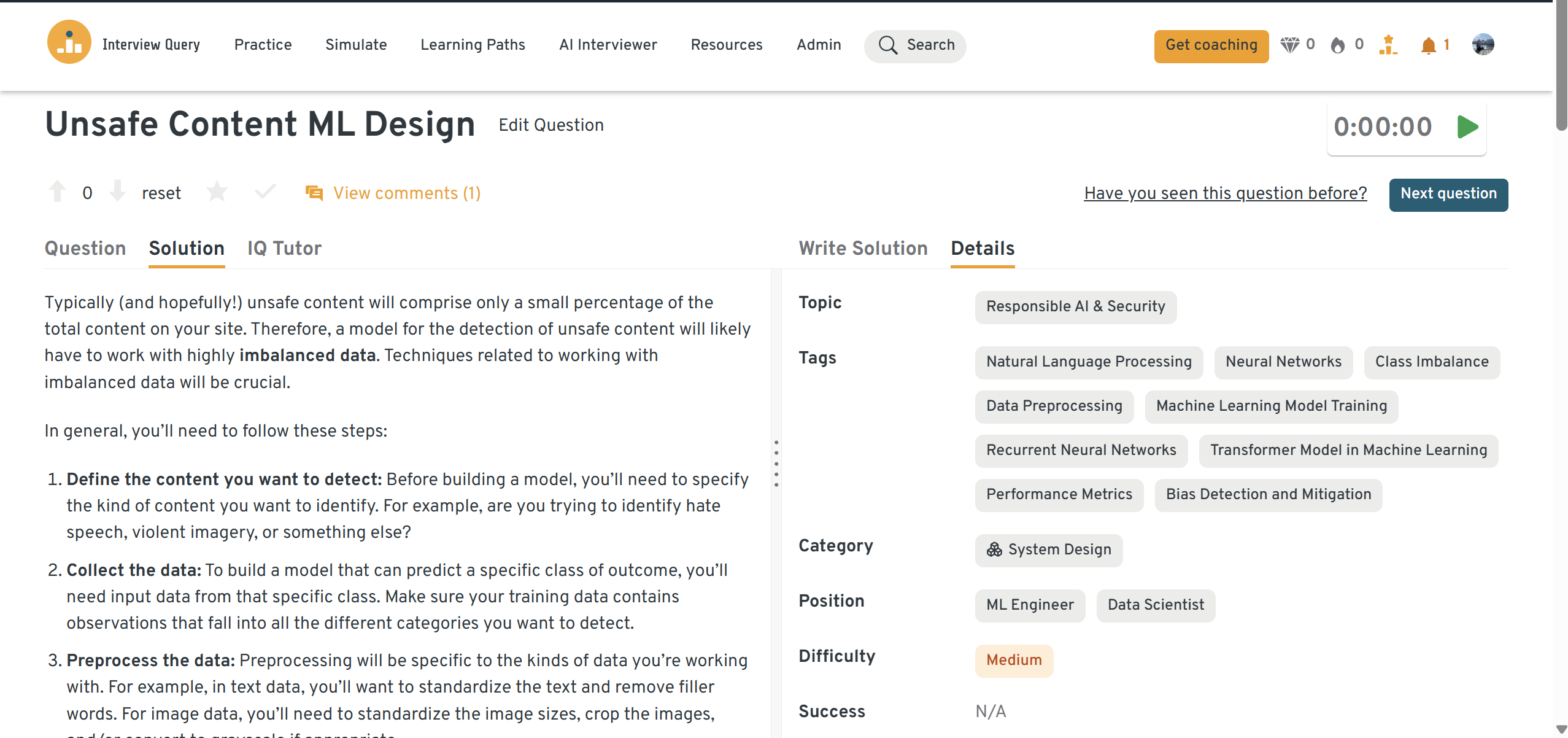
How would you design a machine learning system to detect unsafe content?
This question explores your ability to design a compliance-sensitive ML system. Start by describing the multi-layered nature of the problem: text, image, and video content each require separate detection models. You could mention using CNNs or vision transformers for image classification, LLM-based toxicity classifiers for text, and multimodal fusion models to combine signals.
Explain how you would handle data labeling and balance precision with recall to minimize false positives. Then outline a review pipeline where the model flags content for human verification and feedback loops improve model performance over time.
Tip: Discuss scalability and ethics together. Meta wants engineers who can detect harmful content quickly without over-censoring legitimate expression.
How would you design a podcast search engine using transcript and metadata?
This question tests how you integrate NLP with information retrieval. Start by explaining how you would process transcripts with automatic speech recognition (ASR) and store both text and metadata in a searchable index. Discuss ranking strategies using term frequency–inverse document frequency (TF-IDF), embeddings, or semantic search powered by transformer-based models.
Then address user experience by highlighting how you’d optimize relevance, query completion, and topic clustering. Close by discussing evaluation metrics such as mean reciprocal rank (MRR) and user satisfaction scores.
Tip: Talk about hybrid retrieval methods. Meta interviewers appreciate candidates who combine traditional search ranking with learned representations to balance speed and precision.
-
This question focuses on latency, personalization, and ranking. Describe the architecture of an autocomplete system that predicts relevant queries as users type. You can mention prefix trees (tries) for efficient lookup and embedding-based ranking models to personalize results.
Explain how you would evaluate the system using metrics like click-through rate, query abandonment rate, and latency. Add that you would run A/B tests to ensure new models improve engagement without harming performance.
Tip: Highlight real-world constraints. Meta interviewers want to hear how you’d handle high query volume, caching, and quick model updates without service disruption.
-
This question challenges you to think about scalability and low latency under heavy load. Start by describing a distributed pub-sub architecture for real-time updates across multiple platforms. Explain how you’d use message queues and caching to propagate comment and reaction updates within milliseconds.
Then discuss handling AI censorship efficiently. You can suggest a hybrid model where static text matching filters common violations and NLP models handle dynamic cases asynchronously to minimize latency.
Tip: Emphasize system reliability. Meta engineers are expected to think about fallback mechanisms. if the AI model fails, moderation should gracefully degrade without breaking the live experience.
Need 1:1 guidance on your interview strategy? Interview Query’s Coaching Program pairs you with mentors to refine your prep and build confidence. Explore coaching options →
Behavioral and communication interview questions
Behavioral questions help Meta assess how you think, collaborate, and adapt in complex technical environments. As a machine learning engineer, you are expected to communicate your reasoning clearly, work with cross-functional partners, and take ownership of model outcomes that impact millions of users. The strongest answers connect your experiences to measurable results and learning moments.
1. What are your strengths and weaknesses?
Meta looks for self-aware engineers who can articulate both technical and interpersonal growth. When talking about strengths, highlight examples that show your ability to design or scale impactful ML systems. For weaknesses, focus on areas you’ve actively improved through feedback or iteration.
Sample Answer: One of my strengths is translating research into scalable production systems. On a recent project, I helped optimize a recommendation model’s deployment pipeline, reducing latency by 20 percent and improving engagement metrics. A weakness I recognized early in my career was hesitating to delegate tasks during high-stakes launches. This often slowed delivery and limited collaboration. After receiving feedback, I started running short syncs to distribute ownership more effectively and track progress through clear checkpoints. Over time, this not only improved efficiency but also strengthened team accountability. The experience taught me that scaling impact requires trust and structured collaboration.
Tip: Always frame weaknesses as areas of growth. Meta values engineers who learn fast and adjust based on data, not perfection.
2. How comfortable are you presenting technical findings to non-technical stakeholders?
This question measures your ability to communicate complex concepts with clarity. ML engineers often present results to product managers, policy teams, and designers who need to understand model impact, not math.
Sample Answer: I’m confident explaining model results at different levels of depth because I always make sure every audience walks away with both clarity and confidence in the data. In one project, I presented findings from a bias-reduction experiment to both engineers and policy teams. Before the meeting, I spoke with policy leads to understand their main concerns about fairness and user sentiment. During the presentation, I used layered storytelling: I showed the technical team model precision-recall curves and false-positive rates, while reframing those same results into user impact metrics for the policy group. This approach aligned both sides on trade-offs and led to a 15% reduction in flagged content bias in the next release cycle. The key was preparation and tailoring. The discussion remained data-driven, yet accessible, which helped the team move forward with confidence.
Tip: Use visuals and analogies. Simplifying technical details without losing accuracy shows communication maturity.
3. What are some effective ways to make ML systems or results more accessible to non-technical people?
This question focuses on your ability to translate ML outputs into insights that others can use.
Sample Answer: I built a dashboard showing real-time precision, recall, and model drift metrics for a moderation model. It allowed policy managers to flag anomalies without writing SQL. I also added tooltips explaining each metric in plain language. This reduced ad-hoc data requests by 35 percent and improved transparency.
Tip: Meta values engineers who make AI interpretable. Show how your work enabled others to make faster, data-informed decisions.
4. Tell me about a time you worked with messy or incomplete data. How did you ensure model reliability?
This question evaluates your attention to data quality and practical problem-solving.
Sample Answer: In one project, our user activity data had inconsistent timestamps across regions. I created a preprocessing pipeline that standardized formats and flagged outliers using anomaly detection. I also added validation checks to ensure feature consistency before training. This reduced data-related errors by 60 percent and stabilized weekly model updates.
Tip: Always link your data cleaning process to measurable impact such as improving model accuracy or reducing deployment failures.
Want to practice real case studies with expert interviewers? Try Interview Query’s Mock Interviews for hands-on feedback and interview prep. Book a mock interview →
How To Prepare For a Machine Learning Engineer Role At Meta
Preparing for a machine learning engineer interview at Meta requires technical depth, product awareness, and strong communication skills. You are expected to not only understand algorithms but also how they scale and influence real-world user experiences. The best preparation combines coding practice, system design training, and the ability to clearly explain your work.
Thinking of becoming a Machine Learning Engineer? This video covers the key skills, benefits, and strategies to stand out in the competitive field of machine learning engineering. Learn how to master algorithms, leverage AI technologies, and chart your path to success this year.
Strengthen your foundation in algorithms and data structures
Meta’s technical screens include algorithm and data structure problems that test logical reasoning and efficiency. Focus on arrays, hash maps, heaps, graphs, and dynamic programming. These questions may not always involve machine learning directly, but they reveal how you structure solutions under time pressure.
Tip: Practice coding problems that simulate large-scale data handling. Sites like Interview Query or LeetCode can help you build speed and accuracy.
Revisit machine learning fundamentals
Be ready to explain and compare algorithms such as linear regression, decision trees, random forests, and neural networks. Meta interviewers will want to see how you reason about model choice, regularization, and evaluation. Expect follow-up questions about how you prevent overfitting, handle missing data, and evaluate model performance.
Tip: Move beyond memorizing theory. Be prepared to explain trade-offs, such as when to choose precision over recall or when interpretability is more valuable than accuracy.
Practice ML system design
System design interviews focus on how you build and scale machine learning pipelines. You should be able to describe your approach to data ingestion, feature engineering, model training, monitoring, and retraining. Familiarity with tools like Airflow, Spark, or Kubeflow can help you describe concrete implementation strategies.
Tip: Think aloud as you design. Meta interviewers evaluate how you approach ambiguity and structure complex ideas, not whether your architecture is perfect.
Review real Meta products and use cases
Studying Meta’s products helps you understand how ML is applied in practice. Look at feed ranking, ad recommendation, content moderation, and personalization systems. Consider the challenges these applications face, such as fairness, privacy, and latency.
Tip: Reading Meta’s engineering blog or research papers gives you valuable context. Referencing real examples in your interview shows initiative and insight.
Refine your communication and collaboration skills
Strong communication is essential at Meta. You will often present your ideas to engineers, product managers, and policy teams. Practice simplifying technical results into business or user impact statements. Using the “situation, action, result” framework helps keep your answers structured and memorable.
Tip: Record yourself explaining a past ML project in under two minutes. This exercise builds confidence and helps you identify areas where your explanations can be sharper.
Strengthen your foundation in algorithms and data structures
Meta’s technical screens include algorithm and data structure problems that test logical reasoning and efficiency. Focus on arrays, hash maps, heaps, graphs, and dynamic programming. These questions may not always involve machine learning directly, but they reveal how you structure solutions under time pressure.
Tip: Practice coding problems that simulate large-scale data handling. Sites like Interview Query or LeetCode can help you build speed and accuracy.
Revisit machine learning fundamentals
Be ready to explain and compare algorithms such as linear regression, decision trees, random forests, and neural networks. Meta interviewers will want to see how you reason about model choice, regularization, and evaluation. Expect follow-up questions about how you prevent overfitting, handle missing data, and evaluate model performance.
Tip: Move beyond memorizing theory. Be prepared to explain trade-offs, such as when to choose precision over recall or when interpretability is more valuable than accuracy.
Practice ML system design
System design interviews focus on how you build and scale machine learning pipelines. You should be able to describe your approach to data ingestion, feature engineering, model training, monitoring, and retraining. Familiarity with tools like Airflow, Spark, or Kubeflow can help you describe concrete implementation strategies.
Tip: Think aloud as you design. Meta interviewers evaluate how you approach ambiguity and structure complex ideas, not whether your architecture is perfect.
Review real Meta products and use cases
Studying Meta’s products helps you understand how ML is applied in practice. Look at feed ranking, ad recommendation, content moderation, and personalization systems. Consider the challenges these applications face, such as fairness, privacy, and latency.
Tip: Reading Meta’s engineering blog or research papers gives you valuable context. Referencing real examples in your interview shows initiative and insight.
Refine your communication and collaboration skills
Strong communication is essential at Meta. You will often present your ideas to engineers, product managers, and policy teams. Practice simplifying technical results into business or user impact statements. Using the “situation, action, result” framework helps keep your answers structured and memorable.
Tip: Record yourself explaining a past ML project in under two minutes. This exercise builds confidence and helps you identify areas where your explanations can be sharper.
Average Meta (Facebook) Machine Learning Engineer Salary
Meta Machine learning engineer (Facebook) in the United States earns among the highest compensation packages in the industry. According to Levels.fyi data, total annual compensation ranges from approximately $320K per year at the E4 level to $700K per year for E6 engineers. The national average package across levels is around $460K annually.
- E4 (Mid-level): $320K per year ($180K base + $120K stock + $20K bonus)
- E5 (Senior-level): $460K per year ($230K base + $170K stock + $30K bonus)
- E6 (Staff): $700K per year ($280K base + $340K stock + $50K bonus)
Compensation varies by region due to cost-of-living adjustments.
- San Francisco Bay: Median total compensation is $480K, with stock awards contributing heavily to long-term pay. (Levels.fyi)
- New York City: Packages average $350K annually. (Levels.fyi)
- Greater Seattle: Typical total compensation is around $420K per year. (Levels.fyi)
Average Base Salary
Average Total Compensation
Meta’s compensation structure combines a high base salary with generous stock grants and performance bonuses. Stock typically accounts for 25–35% of total compensation, reinforcing Meta’s focus on ownership and long-term value creation.
FAQs
What does a Meta machine learning engineer do?
Meta’s ML engineers design, train, and deploy large-scale models that power recommendations, personalization, integrity, and generative AI systems. They work with cross-functional teams to improve user experience, optimize infrastructure, and translate research into production-ready solutions.
What is the interview process like for a Meta machine learning engineer?
The process includes a recruiter screen, one or two technical interviews, and an onsite or virtual loop covering ML system design, applied modeling, and behavioral rounds. A final committee review ensures consistent evaluation across all candidates.
How does Meta evaluate candidates during interviews?
Candidates are assessed on technical depth, problem-solving ability, system thinking, and communication. Meta values engineers who can balance model performance with fairness, efficiency, and product impact.
How long does the Meta hiring process take?
The process typically takes two to six weeks, depending on scheduling and role urgency. Feedback is usually shared within one to two weeks after interviews.
What are the required machine learning skills for Meta?
You should have strong coding skills in Python, solid understanding of ML theory and evaluation metrics, and experience with large-scale model deployment, optimization, and experimentation frameworks.
How can I make my resume stand out while applying for an MLE role at Meta?
Highlight projects with measurable impact, such as performance gains, scalability improvements, or user experience enhancements. Quantify results and emphasize collaboration or leadership in cross-functional projects.
What should I focus on when preparing for Meta’s ML engineer interview?
Review ML theory, system design for data pipelines, coding efficiency, and Meta-style applications like ranking, personalization, and content moderation.
How can I align my responses with Meta’s mission and values?
Show that you care about building responsible, human-centered AI. Connect your examples to Meta’s focus on community, inclusion, and scalable innovation that improves global connection.
What is the work culture like for ML engineers at Meta?
Meta promotes collaboration, experimentation, and fast iteration. Engineers are encouraged to prototype quickly, test ideas, and deliver measurable improvements at scale.
How do I stand out as a machine learning engineer candidate at Meta?
Show ownership, clear communication, and real-world impact. Explain how your models solved problems, the trade-offs you made, and how your decisions improved system performance or user outcomes.
Start Your Meta Machine Learning Engineer Interview Prep Today!
The Meta machine learning engineer interview is one of the most challenging and rewarding in the industry. It’s your chance to design models that power global systems, improve billions of user experiences, and push the boundaries of applied AI. Success depends on strong fundamentals, clear communication, and the ability to connect technical reasoning with real product impact.
Take the next step in your preparation by practicing with real questions and expert feedback. Explore Meta machine learning interview questions, join a mock interview session to simulate the experience, or follow the ML system design learning path to master the topics Meta values most. Every question you solve brings you closer to landing the role and making an impact at scale.