
Databricks Interview Questions and Hiring Process Guide (2025)


Introduction
Navigating Databricks interview questions is your first step toward joining one of the most sought-after companies in tech, known for transforming the data and AI landscape. The Databricks interview process is more than just a hiring funnel—it is a competitive gateway into a $62 billion powerhouse driving how enterprises harness the value of their data.
As part of the Databricks hiring process, candidates encounter unique, data-driven challenges that reflect the company’s real-world impact. This guide explores what to expect during the Databricks interview experience, from behavioral rounds to technical case studies tailored for roles in data engineering, supply chain, and beyond. With over 3,000 hires planned for 2025 and top-rated employee satisfaction, Databricks offers not only generous compensation but also the opportunity to shape the future of AI. If you’re ready to level up your career, understanding how to navigate their interview strategy is essential.
Why Work at Databricks?
If you’re aiming to grow your career while maximizing financial upside, Databricks culture offers an ideal balance of ownership, innovation, and reward. Databricks is in hyper-growth mode, with 50 to 60 percent year-over-year revenue increases and over 15,000 customers, including 60 percent of the Fortune 500. Its open-source roots in Apache Spark and Delta Lake fuel a culture where engineers solve high-impact problems at a massive scale.
You’ll join “Championship Teams” that value autonomy and accountability, all while working on AI and data infrastructure that drives real enterprise value. Compensation is a major draw, too. The average Databricks salary for software engineers is $457,000 in total comp, with equity refreshes common and annual grants reaching over $200K. Databricks is expected to IPO soon, creating wealth-building potential as valuations climb beyond $62 billion. This is your chance to be part of a company with unmatched growth, a builder mindset, and a customer-obsessed focus on impact.
Challenge
Check your skills...
How prepared are you for working at Databricks?
What Is the Interview Process Like at Databricks?
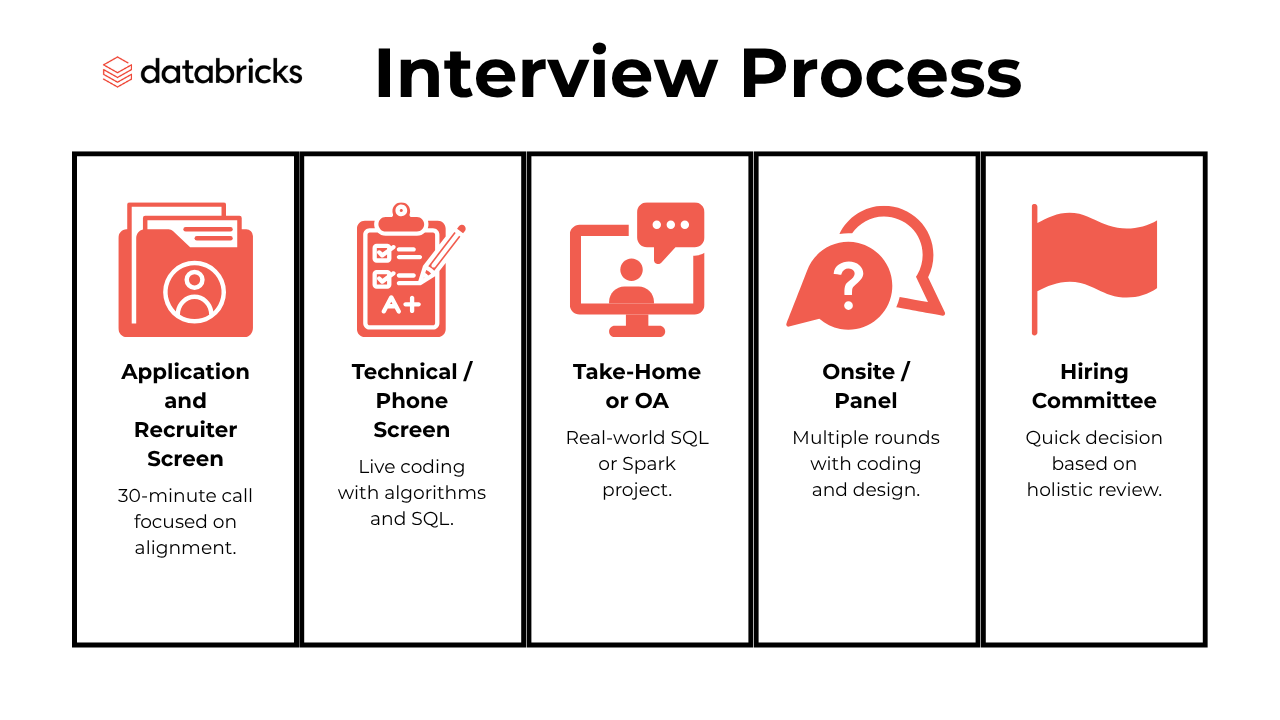
Your Databricks interview experience is designed to be thorough yet efficient, typically spanning 2–5 weeks with rapid feedback at each stage. Here is how it typically goes for data and tech roles:
- Application and Recruiter Screen
- Technical / Phone Screen
- Take-Home or OA
- Onsite / Panel
- Hiring Committee
Application and Recruiter Screen
Your journey begins with a streamlined application process, followed by the Databricks recruiter call. Here, you’ll discuss your background, technical skills, and motivation for joining Databricks. Recruiters are looking for alignment with the company’s mission and a strong foundation in data or software engineering. On average, this stage lasts about 30 minutes and sets the tone for your candidate experience. Databricks recruiters share your profile with engineering leads for team matching, and you’ll receive clear guidance on next steps. Candidates report that this stage is transparent and supportive, with 85% recommending the process to friends and a 4.3⁄5 overall satisfaction rating.
Technical / Phone Screen
The technical phone screen (often called the Databricks phone screen) is your chance to showcase problem-solving skills in real time. You’ll spend about 60 minutes with an engineer, working through LeetCode-style questions using CoderPad or a similar online IDE. Expect questions that test your depth in algorithms, data structures, and sometimes SQL or Spark fundamentals. Databricks maintains a high bar, with difficulty ratings averaging 3.1⁄5 and a focus on both code correctness and communication. For many roles, you’ll also have a Databricks hiring manager interview, which blends technical depth with behavioral insights, ensuring you’re evaluated for both technical fit and team alignment.
Take-Home or OA
If you progress, you may be invited to complete a take-home assignment or online assessment (OA). These tasks are designed to mirror real Databricks challenges—think advanced SQL queries, Spark jobs, or data engineering case studies. You’ll typically have 48–72 hours to complete the task, with most candidates spending 3–5 hours. The OA is a strong predictor of onsite performance, and 86% of candidates who excel here move forward. This stage is your opportunity to demonstrate practical problem-solving, code quality, and an understanding of scalable data systems.
Onsite / Panel
The Databricks onsite interview is an intensive, multi-hour experience featuring a mix of technical and behavioral rounds. You’ll face a panel interview with engineers, managers, and sometimes a Databricks cross-functional interview with a PM or design partner. Rounds include coding (algorithms, concurrency), system design (often via Google Docs), and behavioral questions about collaboration and conflict resolution. The panel format ensures a holistic review, with each interviewer scoring you independently. Databricks onsite interviews are known for their rigor—candidates rate them among the most challenging in tech, but also praise the transparent feedback and supportive environment.
Hiring Committee
After the onsite, your candidacy is reviewed by the Databricks hiring committee. This group evaluates all feedback, references, and your overall trajectory to make a holistic decision. The process is fast—most candidates receive a decision within days, with the full process rarely exceeding five weeks. Databricks is committed to quick, transparent feedback loops, so you’ll never be left waiting in the dark. The final step may involve a reference check or a brief executive review, ensuring only the strongest candidates receive offers.
Most Common Databricks Interview Questions
To help you succeed in your interview, we’ve organized the most commonly asked Databricks interview questions by role and topic, covering technical, behavioral, and system design challenges. For more specific questions, find the roles linked below:
- Databricks Software Engineer interview questions
- Databricks Data Engineer interview questions
- Databricks Data Scientist interview questions
- Databricks Business Analyst Interview Questions
- Databricks Business Intelligence Interview Questions
- Databricks Data Analyst Interview Questions
- Databricks Growth Marketing Analyst Interview Questions
- Databricks Machine Learning Engineer Interview Questions
- Databricks Product Manager Interview Questions
- Databricks Research Scientist Interview Questions
Coding & Algorithms
Databricks coding interview questions test your core problem-solving skills through SQL challenges, algorithm design, and clean code execution:
1. Write a query to find the top five paired products and their names
To find paired products often purchased together, join the transactions table with the products table to get product names. Then, use a self-join on the resulting table to pair products bought by the same user at the same time. Filter out duplicate pairs by ensuring the first product name is alphabetically less than the second. Finally, group by product pairs, count occurrences, and sort by frequency to get the top five pairs.
To solve this, first count the frequency of comments per user by joining the users and comments tables. Then, group by the frequency to create a histogram. Finally, use a self-join to calculate the cumulative distribution by summing frequencies for all values less than or equal to the current frequency.
To solve this, transform the payments table to consolidate sender and recipient transactions into one column. Filter transactions based on the signup date, transaction date, and successful payment status. Group the filtered data by user and calculate the total transaction volume, then count users whose total exceeds 10000 cents.
4. Find the number of possible triangles from a list of side lengths
To solve this, iterate through all combinations of three side lengths from the list and check if they satisfy the triangle inequality. If they do, count them as valid triangles. Use the combinations function from the itertools library and a helper function to validate the triangle inequality.
5. Given an integer N, write a function that returns all of the prime numbers up to N
To solve this, iterate through all numbers up to (N) and check each for primality by ensuring it’s not divisible by any number other than 1 and itself. Optimizations include checking divisors only up to the square root of the number and considering specific number-theoretic properties of primes.
System Design
The Databricks system design interview evaluates how you architect scalable, resilient, and performant solutions using real-world data scenarios from the Databricks platform:
6. How would you build the recommendation algorithm for type-ahead search for Netflix?
To design a type-ahead search algorithm for Netflix, start with prefix matching using a TRIE data structure to efficiently map input strings to output strings. Incorporate user preferences and contextual data by clustering user profiles into feature sets, such as “Coen Brothers Fan.” Use Bayesian updates to refine recommendations based on user behavior and scale the system with layers for mapping profiles, prefix matching, and caching condensed user profiles. Gradually grow the cache domain to ensure scalability and performance.
To design a unified commenting system, you can use a distributed architecture with a central server that aggregates and synchronizes comments and reactions from all platforms. Implement persistent storage for comments and reactions to enable later analytics. Use WebSocket or similar technologies for real-time updates, ensuring reaction counts are displayed instantly. For AI censorship, dynamic NLP methods can be recommended for better adaptability to context, despite potential latency issues.
8. Design an end-to-end data pipeline for predicting bicycle rental volumes
To solve this, the pipeline should include data ingestion from multiple sources, cleaning and normalization, feature engineering, and serving data for predictive modeling. Tools like Airflow for orchestration, Spark for transformation, and a data warehouse for storage and analytics can be used. The pipeline must handle schema evolution, missing data, and ensure consistent joins across sources, outputting a clean feature-engineered table for modeling.
9. Design a database schema for a blogging platform
To design the schema, create tables for Blog Posts, Blog Authors, and Engagement, each with appropriate fields and constraints. Define relationships such as one-to-many between authors and posts, and one-to-one between posts and engagement. Apply constraints like primary keys, foreign keys, and enums for specific fields to ensure data integrity and usability.
To handle unstructured video data, the pipeline involves three key steps: collecting and indexing video metadata, tagging user-generated content, and binary-level data collection. Automated content analysis using machine learning techniques like image recognition, object detection, and NLP transcription can further enrich the dataset, making it suitable for downstream processing.
Behavioral & Ownership
Expect Databricks behavioral interview questions that explore your ability to take ownership, adapt under pressure, communicate across teams, and align your actions with business outcomes.
11. How would you as a Supply Chain Manager handle a product launch delay?
In a data-driven organization like Databricks, you should focus on proactively communicating the delay through clear messaging informed by real-time customer sentiment data. Use predictive analytics to prioritize allocation for key accounts and revise inventory planning models to manage downstream impacts. Afterward, lead a cross-functional retrospective using data pipelines to uncover root causes and ensure future launches are more resilient.
When working across technical and non-technical teams at Databricks, communication breakdowns can occur due to differing levels of data fluency. You should give an example of a time when your data analysis was misinterpreted, explain how you recalibrated your communication style to be more outcome-focused, and show how using shared dashboards or visualizations helped bridge the gap. This demonstrates adaptability and a user-first mindset, which are essential at Databricks.
13. How comfortable are you presenting your insights?
Presenting insights at Databricks means translating complex data into actionable decisions. You should explain how you tailor visual storytelling for different audiences using tools like Power BI, Tableau, or Databricks SQL dashboards. You can also share how you remain confident presenting to executives by preparing around business impact and encouraging dialogue to make technical insights more collaborative.
This scenario requires data-backed negotiation and long-term thinking. You should describe how you would use analytics to build a Total Cost of Ownership model and identify levers like volume commitments or performance-based incentives. While short-term flexibility may be needed, emphasize how you’d use Databricks’ data platform to monitor supplier risk, simulate pricing scenarios, and develop a roadmap for future supplier diversification.
How to Prepare for a Databricks Interview
Preparing for your Databricks interview means combining technical rigor with a strong understanding of the company’s culture and process. Start by reviewing the databricks interview process so you know what to expect at each stage, from the initial recruiter call to the technical rounds and the final hiring committee review. Early on, you may receive a Databricks take-home assignment—these mirror real-world challenges and are a key filter, so practice building robust Spark jobs or advanced SQL queries under time constraints. Candidates who excel here are 86% more likely to advance to onsite interviews.
Technical preparation is critical. The coding rounds are known for their difficulty, with many questions at the LeetCode hard level. Use LeetCode databricks tagged problems and focus on data structures, algorithms, concurrency, and graph theory. Practicing mock interviews, especially those simulating the Databricks environment, will help you build confidence and speed. When tackling problems, start with a brute-force solution to demonstrate a clear approach, then discuss optimizations—this is a valued strategy in Databricks interviews.
Don’t overlook Spark and Delta Lake expertise. You’ll likely face Delta Lake interview questions covering ACID transactions, schema enforcement, time travel, and real-time analytics. Mastering these concepts is essential, as Delta Lake is a “silent killer” for even experienced candidates. Finally, immerse yourself in Databricks’ collaborative culture and leadership principles—interviewers weigh cultural fit heavily, so be ready to share STAR stories that showcase teamwork, continuous learning, and customer obsession. This holistic preparation will set you apart and boost your chances of success.
Salary at Databricks
Average Base Salary
Average Total Compensation
FAQs
What are the toughest Databricks interview questions and answers?
Expect multi-part case studies that mix SQL, Spark, and system design while probing your approach to data governance and security. Prepare concise stories using the STAR format, then practice coding on Databricks notebooks so you can explain each step aloud. Review open-source commits and recent features so you can add opinionated insights that show you are already thinking like a Brickster.
How long is the Databricks hiring process?
The Databricks hiring process usually spans three to six weeks from recruiter screen to offer, although executive approvals can add extra days near quarter-end. You will move through a phone screen, a technical round, a virtual onsite with five to six interviews, and a final values conversation before compensation is discussed.
How do I get hired as a Databricks engineer?
Start by mastering Spark and Lakehouse design, then publish projects that showcase cost-efficient pipelines. When you network at meetups, ask how teams decide to hire Databricks engineer talent and tailor your resume to those signals. Practice whiteboard sessions that connect architecture choices to customer impact, because Databricks rewards engineers who think in business outcomes.
What happens during the Databricks technical interview?
The Databricks technical interview begins with a live coding exercise in a shared notebook where you optimize a data-processing task. You then discuss design trade-offs, followed by questions on scalability, fault tolerance, and how your solution aligns with Delta Lake best practices.
Are Databricks interviews different for interns?
Yes. Databricks interviews for interns are shorter, with one technical and one behavioral round focused on learning potential rather than deep production experience. Interviewers weigh coursework, hackathon projects, and curiosity more heavily while still checking for cultural alignment and a growth mindset.
Conclusion
Preparing for Databricks means more than memorizing answers. It means understanding how the company thinks about data, culture, and scale. Now that you’ve explored key Databricks interview questions, you’re ready to take the next step. Start building mastery with our Databricks Data Analytics Learning Path, which focuses on the most relevant technical skills. If you need inspiration, read this success story from a data scientist who turned a take-home challenge into a full-time offer. For deeper prep, explore our complete Databricks questions collection to benchmark your skills and fill in gaps.
Discussion & Interview Experiences