

Adobe Interview Questions in 2025


Introduction
Adobe is far more than a design brand. With platforms like Creative Cloud, Experience Cloud, and Document Cloud, it shapes how people create, market, and collaborate in the digital age. Its recent innovations include Firefly, a generative AI engine for creatives, and Experience Platform, which enables real-time personalization for global enterprises. These products highlight Adobe’s reach across industries and its reputation as one of tech’s most creative employers.
Every month, thousands of applicants search for Adobe interview questions and want clarity on the Adobe interview process. In this guide, you will find a stage-by-stage breakdown of how interviews unfold, common question themes, insights into Adobe levels and compensation data, and targeted strategies to help you prepare. Whether your path is data, design, or product, this playbook gives you the context and structure to approach your interview with confidence.
Why Work at Adobe?
When candidates search for why to work at Adobe, they’re often weighing more than just compensation—they’re drawn to the company’s creative legacy, inclusive culture, and clear growth path. From your first day, you’ll be aligned to one of several Adobe levels, which map to role expectations and career progression across engineering, product, and design tracks.
Career Growth & Levels at Adobe
The Adobe levels framework offers a transparent path from Software Engineer I through II, Senior, Lead, and up to Sr. Principal and Fellow. Promotions typically occur on an annual cadence during performance reviews, and leveling plays a direct role in project scope, compensation bands, and mentorship expectations. Clear growth trajectories and cross-functional mobility mean you’re never siloed.
Purpose‑Driven Culture
Adobe’s mission, Creativity for All, extends beyond its products. Employees receive an annual creativity allowance to fuel personal passion projects, and the Adobe For All Summit brings together diverse voices across the company to celebrate inclusion, equity, and impact. You’re not just building tools; you’re empowering others to create, tell stories, and solve problems.
Tech & Product Impact
Adobe interviewers often reference marquee innovations like Firefly, the company’s generative AI engine for creatives, or the experience platform, which powers real-time personalization for global brands. These products not only reflect Adobe’s technical depth but also offer rich material for storytelling during interviews.
What’s Adobe’s Interview Process Like?

Recruiter Screen
This introductory call covers role logistics, a resume walkthrough, timeline expectations, and a preliminary check on salary band alignment. Recruiters may also ask a few surface-level questions about your interest in Adobe and how your background aligns with the role.
You’ll want to refine a concise “elevator pitch” that summarizes your background in about a minute. Focus on two or three experiences that are most relevant to the Adobe role you’re pursuing and be ready to walk through them in a way that connects naturally to the job description. Salary expectations may come up as well, so it’s important to research Adobe’s compensation ranges for your role in advance. Having a thoughtful range ready, while also emphasizing that you’re open and focused on team fit, demonstrates professionalism.
This is also a good time to convey genuine enthusiasm for Adobe. Mention one or two products that stand out to you, and explain why they excite you or how you’ve used them. Showing that you have a personal connection to Adobe’s offerings helps you stand out in what could otherwise feel like a purely logistical conversation.
Tip: Practice your pitch in front of a mirror or record yourself; recruiters value clarity and confidence more than polished jargon. If you want to stand out, here are top 17 Python projects to boost your resume.
Technical/Case Rounds
The technical and case rounds are where the real evaluation begins, and this is where Adobe technical interview questions will test both your problem-solving skills and your ability to communicate clearly. For technical roles, preparation often means practicing coding problems that fall within common patterns like arrays, hash maps, SQL queries, and dynamic programming. Time yourself as you solve these so you get comfortable working under pressure.
If you’re interviewing for a mid- or senior-level engineering position, you should also review system design. A helpful approach is to start by clarifying requirements, then walk through a structured framework, considering clients, APIs, services, databases, and scaling trade-offs.
For data or business-facing roles, the emphasis is often on interpreting ambiguous problems and creating structured frameworks to solve them. You might be asked how to diagnose a drop in Adobe Creative Cloud subscriptions, for example, and a strong answer would outline what data you’d examine, potential hypotheses, and how you’d design an experiment to test your assumptions.
Regardless of role, speaking your thought process out loud is crucial. Interviewers are as interested in how you break down problems as they are in whether you land on the right answer.
Tip: Before diving into code, narrate your plan. Adobe interviewers often give partial credit for structured thinking even if you don’t finish. You can practice questions on Interview Query.
Behavioral & Values Round
In the behavioral and values round, you’ll encounter Adobe behavioral interview questions designed to assess alignment with Adobe core values like “Genuine,” “Innovative,” and “Involved.” The best way to prepare is to build a library of STAR stories, structured examples that follow the Situation, Task, Action, and Result framework. Aim for six to eight detailed stories that each highlight different aspects of your professional experience, such as collaboration, problem-solving, leadership, or resilience.
When possible, anchor your stories in measurable outcomes, since quantifiable impact makes your contributions more credible and memorable. For instance, rather than saying you improved engagement, you might share that you increased engagement by 25% through a specific redesign of the content funnel.
As you practice these stories, rehearse them aloud so they flow naturally, and try to explicitly link your answers back to Adobe’s values. Saying something like “This was a time when I needed to be genuinely transparent with my team” signals clearly to the interviewer that you understand and embody the values Adobe cares about.
Tip: Keep a one-line “value tag” ready for each STAR story so you can easily connect your answer to Adobe core values in the moment.
Path for Experienced Hires
For more experienced candidates, the interview often shifts toward evaluating leadership, influence, and impact at scale. The Adobe interview questions for experienced candidates frequently touch on architecture choices, cross-functional influence, and how you’ve delivered measurable business outcomes. To prepare, think through situations where you led without formal authority, and be ready to describe how you built consensus and overcame resistance.
When asked about design or strategic decisions, don’t stop at the technical details; also explain the reasoning behind your choices, the trade-offs you considered, and the business value they created. One of the most effective ways to frame answers at this level is to use a structure that begins with the context, moves into the key decision you made, describes how you managed stakeholders, and ends with the impact you delivered. By emphasizing ownership and quantifiable results, whether that’s cost savings, faster performance, or higher adoption rates, you show that you can think beyond execution and operate as a leader who drives outcomes at scale.
Tip: Highlight not just what you built, but how your decision influenced revenue, adoption, or customer experience. Executives care most about business impact.
Most Asked Adobe Interview Questions
Role‑Specific Interview Guides
- Software Engineer → Adobe Software Engineer Interview Guide
- Data Engineer → Adobe Data Engineer Interview Guide
- Machine Learning Engineer → Adobe Machine Learning Engineer Interview Guide
- Data Scientist → Adobe Data Scientist Interview Guide
- Product Manager → Adobe Product Manager Interview Guide
Technical Questions
Adobe technical interview questions often blend real-world data challenges with fundamental coding and SQL logic. Expect scenarios that test your ability to handle business analytics tasks at scale, automate logic in Python, and design systems that power Adobe’s marketing and creative cloud tools.
Beginner
Group a list of sequential timestamps into weekly lists starting from the first timestamp
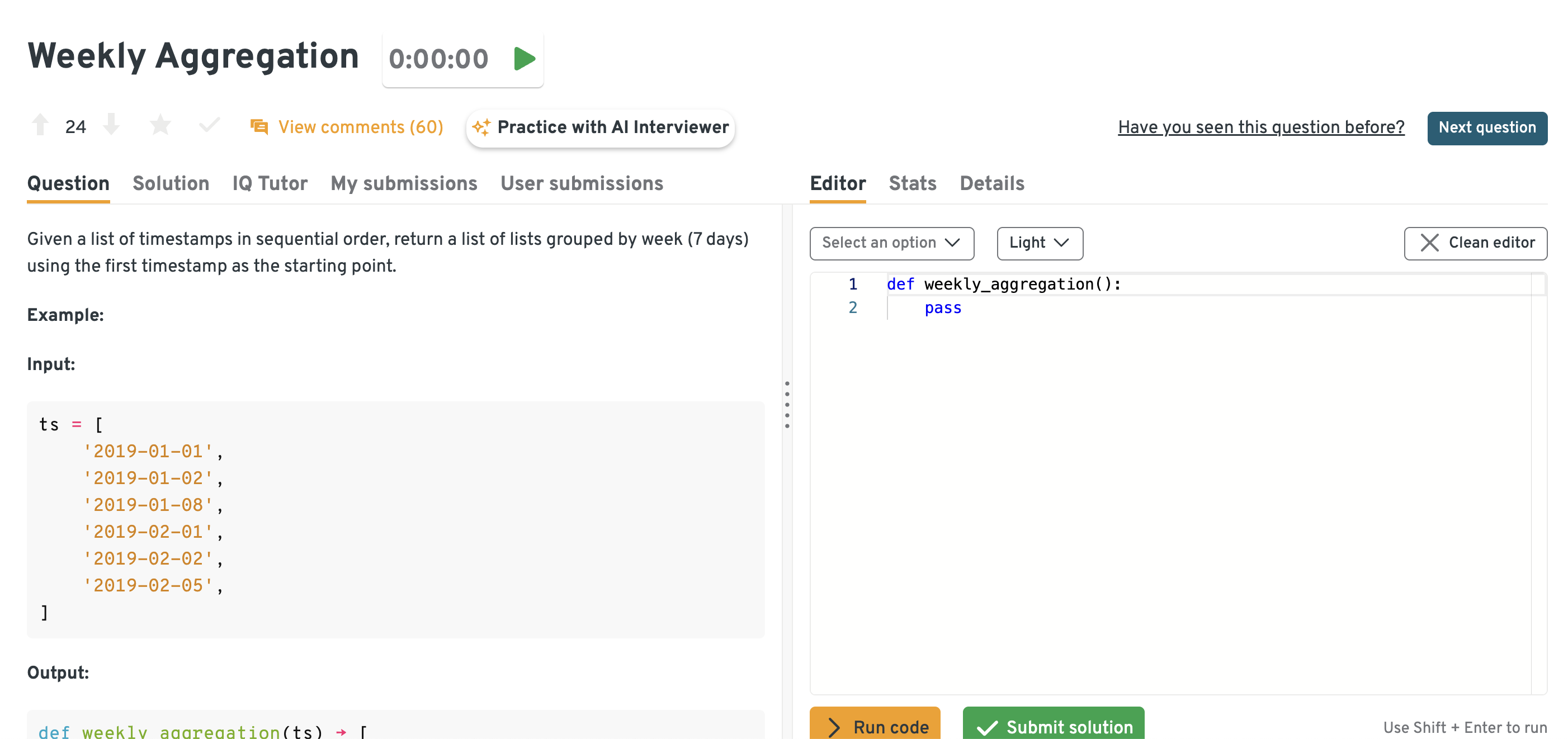
You can attempt this question directly on the Interview Query dashboard. Working through it there allows you to practice in a guided environment, check your solution against community answers, and get a feel for the kinds of variations that might come up in an actual Adobe interview.
Approach this by anchoring on the earliest timestamp and then dividing each subsequent event’s offset by seven days to form weekly buckets. In SQL you can compute a
week_idby taking the difference in days and integer-dividing by seven, while in Python you can assign buckets with pandas. Pay close attention to edge cases like timezone handling or missing days. This is relevant to Adobe because product logs and asset usage often need to be grouped into custom weekly cohorts.Tip: Always test edge cases like timestamps that fall exactly on the 7-day boundary.
Replace words with their stems
This problem asks you to implement a simplified stemming algorithm. You can approach it by iterating through words and replacing them with the shortest root that matches a given dictionary, ensuring you handle overlaps correctly. This is especially relevant in NLP-heavy contexts like Adobe search features.
Tip: Watch for overlapping roots. Shorter matches should take precedence.
Calculate the first touch attribution for each user that converted
The solution is to isolate each user’s earliest marketing touch event and then attribute conversions back to that channel. In SQL, partition by user and order events by time, selecting the first row with
ROW_NUMBER() = 1. Once attribution is determined, aggregate across channels to compute counts or conversion rates. This resembles Adobe’s marketing cloud use cases for attribution.Tip: Double-check if you should filter only on users that eventually converted.
Write a query that finds the third purchase of every user
To solve, order each user’s transactions by date and then select the third row for each. This can be done with
ROW_NUMBER()orRANK(). Handling ties or multiple purchases on the same day is important. Adobe commerce data often requires this type of sequence analysis.Tip: Confirm business rules. Should multiple purchases on the same day count separately?
Find the most frequently used font in a set of Adobe design projects
SELECT font_name, COUNT(*) AS usage_count
FROM design_assets
GROUP BY font_name
ORDER BY usage_count DESC
LIMIT 1;
Tip: In real analytics, frequency often needs to be normalized (e.g., by project size).
Intermediate
Select the top 3 departments with at least 10 employees and rank them based on salaries
This problem asks you to select the top three departments with at least ten employees, ranked by average salary. The approach is to group by department, use
HAVING COUNT(*) >= 10, computeAVG(salary), and then order descending with aLIMIT. The subtlety is ensuring that only large enough departments are included. This is relevant to Adobe because compensation analytics mirrors filtering and ranking logic.Tip: In real analytics, frequency often needs to be normalized (e.g., by project size). You can review this ultimate SQL cheat sheet to ace your SQL interview.
Find the first recurring character in a string
Iterate through the characters of the string while keeping track of those you’ve already seen in a set. The first time you encounter a duplicate, return it. This requires only linear time and is a strong test of hashing fundamentals. In Adobe analytics pipelines, this type of logic is mirrored in deduplication tasks.
Tip: Be ready to explain why you chose
AVGinstead ofMEDIAN.Remove stop words from a sentence
Begin by defining a set of stop words and then filtering the tokens of the sentence against it. In Python, sets allow O(1) lookups for each word. The result is a cleaned-up text string that is more useful for downstream analysis. Adobe would care about this because content indexing often requires filtering noise.
Tip: Mention time complexity—this runs in O(n).
Write a query to forecast the budget of all projects
This query compares actual spending against projected budgets to find projects running over. You compute aggregated spend per project and filter where
SUM(cost) > budget. Reporting this result provides actionable monitoring. For Adobe, project cost controls often surface in BI dashboards.Tip: Clarify whether forecasts should include in-progress costs or just actuals.
Identify the top 5 countries by number of Adobe Creative Cloud subscriptions
SELECT country, COUNT(*) AS subs
FROM subscriptions
WHERE product = 'Creative Cloud'
GROUP BY country
ORDER BY subs DESC
LIMIT 5;
Tip: Normalize by population if the question is about market penetration, not raw counts.
Experienced
Design a classified to predict the optimal moment for a commercial break during a video
The task is to design a system that inserts ads into video streams without degrading user experience. You’d start by defining constraints like frequency caps and user churn risk, then design a classifier or reinforcement learning system to optimize placement. Data collection and feedback loops are crucial for refinement. Adobe’s media and ad products face this challenge at scale.
Tip: Highlight fairness. Avoid inserting ads in culturally or contextually sensitive moments.
Build the recommendation algorithm for type-ahead search
Here you design an autocomplete system with low latency. You’d use prefix indexes for fast lookups, a relevance ranking model, and caching for popular queries. It also requires handling typos and personalization. Adobe search services rely heavily on these principles.
Tip: Mention latency constraints. Sub-100ms responses are critical for search UX. You can find more questions about top 9 machine learning algorithm interview questions on Interview Query.
Create a recommendation engine using the data for any user looking for a new rental unit
This problem is about building a recommender for property listings, which extends to Adobe in recommending content assets. The standard solution is two-stage: candidate generation followed by re-ranking with contextual signals. Cold-start handling and fairness constraints are critical for adoption.
Tip: Address cold start by falling back on popularity-based or demographic filters. If you want to practice more, here are top 32 data modeling interview questions on Interview Query.
Write a query to detect anomalies in daily Adobe Experience Cloud events
SELECT event_date, COUNT(*) AS total_events
FROM experience_logs
GROUP BY event_date
HAVING COUNT(*) > AVG(COUNT(*)) OVER () * 1.5
OR COUNT(*) < AVG(COUNT(*)) OVER () * 0.5;
Tip: Explain why you picked a threshold (e.g., 1.5x) and how you’d refine it in production.
Behavioral & Scenario‑Based Adobe Interview Questions
Adobe scenario-based interview questions typically explore how you navigate ambiguity, influence teams, and think from a customer-first perspective. Many prompts touch on people leadership, cross-functional collaboration, and designing with empathy.
Beginner
Tell me about a time you worked with a product manager to prioritize analytics needs
Adobe wants to see if you can partner effectively with PMs and weigh trade-offs. Show that you framed analytics asks in terms of ROI and focused on the highest-impact deliverables.
Example: “In my last role, our PM wanted three new dashboards at once. I suggested ranking them by user impact and feasibility. We agreed to first launch the customer engagement dashboard, which directly influenced retention, and pushed the other two into later sprints. This kept us focused while still addressing longer-term needs.”
Tip: Use phrases like “impact on business outcomes” and “trade-offs” to show structured thinking.
Give an example where you had to advocate for a customer experience improvement using data
This question explores whether you can take raw data and turn it into a story that influences change. Adobe is looking for evidence that you think about users first and that you can frame data not just as numbers but as customer pain points. Your response should highlight how you identified a problem, quantified it with available data, and then pushed for a design or process improvement that led to a measurable result.
Example: “While analyzing survey feedback, I noticed a recurring complaint about page load times. I combined that with funnel data showing a 15% drop-off during checkout. Presenting this to the product team led to a performance fix, which improved conversions by 10% the next month.”
Tip: Always close with measurable impact, not just the recommendation.
Describe a conflict you had with engineering over implementation feasibility
At a beginner level, the focus is on how you handle disagreements constructively rather than on managing large teams. Adobe wants to know if you can stay collaborative when technical constraints clash with analytics goals.
Example: “Engineering pushed back on adding a new metric because of heavy pipeline changes. I asked which parts were hardest to implement, and we agreed to prioritize one core event instead of five. This gave product a reliable metric while reducing engineering workload.”
Tip: Show empathy for engineering limits while staying persistent about the business need.
Could you identify why engagement dropped on a new feature in Adobe Analytics?
The first step is to clarify what success looked like before the drop: was it DAU, retention on the feature, or completion of a workflow? Then, align rollout timing with when the decline began to rule out confounders like seasonality or bugs. A solid solution involves cohort analysis (new users versus existing ones), funnel breakdowns (where drop-offs occur), and segmenting by entry point or geography. The key is to separate correlation from causation: for instance, a simultaneous UI update may explain declines. Adobe values candidates who don’t stop at diagnosis but propose next steps, such as running an experiment to test whether onboarding or feature discoverability improvements reverse the trend.
Example: “I first validated the timing of the drop against rollout logs and confirmed no bugs were reported. I segmented users by tenure and found new users weren’t engaging, while existing users behaved normally. I recommended improving onboarding visibility. A subsequent A/B test boosted new-user adoption by 12%.”
Tip: Demonstrate how you separate correlation from causation and suggest next steps.
How do you handle an ambiguous request like “understand why churn increased”?
Here, Adobe is testing whether you can bring structure to ambiguity. First, clarify what churn means in context: subscription cancellations, reduced usage, or plan downgrades. Then, align definitions with stakeholders so your analysis has credibility. Next, explore leading indicators such as NPS feedback, login frequency, feature usage trends, and cancellation survey results. Prioritize by high-impact cohorts (e.g., enterprise vs SMB, region, or customer tenure) and visualize drivers in a dashboard to monitor over time.
Example: “I clarified whether churn meant cancellations or downgrades. Then I segmented churn by tenure and noticed spikes among users who joined after a pricing change. I proposed analyzing onboarding feedback and testing revised messaging. This narrowed the root cause and informed a targeted intervention.”
Tip: Show that you clarify definitions first before diving into analysis.
Intermediate
Tell me about a time you led a project with ambiguous or incomplete requirements
Intermediate candidates are expected to show leadership in ambiguous environments. Adobe uses this question to test resilience, structure, and communication when details are unclear.
Example: “I was tasked with ‘improving reporting for marketing.’ I reframed it into hypotheses, drafted an initial dashboard, and shared early versions with stakeholders. Their feedback shaped the final product, which increased campaign ROI tracking by 20%.”
Tip: Emphasize iteration. Adobe values progress over perfection in ambiguity.
Share an example of resolving a disagreement between cross-functional stakeholders
At this stage, Adobe looks for candidates who can act as connectors across departments. This question is about conflict resolution and facilitation skills, especially when different groups have competing priorities.
Example: “Marketing wanted to optimize for clicks, while product cared about signups. I facilitated a joint session, clarified goals, and proposed a blended KPI that balanced both. Both sides agreed, and we launched a unified reporting framework.”
Tip: Frame yourself as the bridge-builder who creates alignment.
Tell me about a time you influenced a product decision without having formal authority
Intermediate candidates need to demonstrate influence, a key part of working at Adobe. Interviewers want to know if you can persuade decision-makers through data, logic, and storytelling, even when you don’t “own” the decision. A strong answer would describe how you built a case, supported it with data and customer empathy, and presented it in a way that shaped the product roadmap. This shows you can move ideas forward by building credibility and trust.
Example: “I found that trial users who engaged with templates converted 30% more. I built a deck showing this impact and presented it to product leads. They prioritized template discoverability, leading to a measurable lift in paid conversions.”
Tip: Influence works best when you combine data with a customer-first narrative.
Tell me how you would design a dashboard to track end-to-end funnel health for Adobe Express
Here, the solution is about structuring data for clarity. Start with acquisition (traffic sources), then activation (onboarding completion), engagement (DAU/WAU, projects created), and monetization (conversions, upsells). Incorporate guardrail metrics like latency or crash rates. Discuss how you’d balance granularity with usability. Adobe values candidates who think not just about data accuracy but also stakeholder usability, since these dashboards are used across product, marketing, and engineering.
Example: “I’d design the funnel across acquisition, activation, engagement, and monetization. The top layer would show KPIs like DAU and conversion rates, with drilldowns for segment-level detail. I’d also include guardrail metrics like crash rates to ensure reliability.”
Tip: Balance detail with usability. Dashboards should inform at a glance but allow deeper exploration.
What would you do if you found conflicting retention numbers across two Adobe dashboards?
This scenario tests problem-solving, not SQL syntax. First, clarify definitions: are the dashboards using different retention windows (D1 vs W1) or different denominators (active users vs registered users)? Next, check the data pipelines: are they pulling from the same source tables and applying consistent filters? Explain how you would reproduce the metric manually using raw event logs as a ground truth check. Adobe wants to see that you don’t panic but methodically debug, and that you understand data trust is foundational to decision-making.
Example: “I confirmed the definitions first and discovered one dashboard used active users while another used registered users as the base. After aligning stakeholders, we standardized retention on active users, which restored trust in reporting.”
Tip: Always tie metric debugging back to building trust in data.
Experienced
Describe a time you had to align executives or senior leaders with conflicting priorities
At the experienced level, Adobe wants to see if you can manage high-stakes situations where leaders disagree. This question tests your ability to navigate organizational politics, frame trade-offs at the strategic level, and keep decisions anchored in business outcomes. A strong answer might involve preparing data-driven scenarios, facilitating structured discussions, and driving alignment without escalating conflict. The ability to influence at the executive level is what separates senior candidates from mid-level ones.
Example: “Two executives disagreed on whether to prioritize feature speed or security. I prepared trade-off scenarios with financial impacts, facilitated a structured session, and helped them agree on a phased rollout that balanced both needs. This avoided delays and preserved trust.”
Tip: Use scenario planning to elevate conversations from debate to decision-making.
Give an example of leading a team through a major change or transformation
Senior candidates are expected to show that they can rally teams through uncertainty or disruption. Adobe uses this question to evaluate change management skills, leadership presence, and the ability to sustain morale. A thoughtful answer would describe how you communicated the “why” behind the change, set realistic expectations, and created a feedback loop to support the team. This demonstrates not only leadership but also emotional intelligence under pressure.
Example: “When we migrated to a new data platform, I communicated the ‘why’ clearly, set phased milestones, and hosted office hours for support. Adoption hit 95% within three months, with minimal disruption.”
Tip: Show empathy and structure. Leaders succeed by guiding both process and people.
Tell me about a situation where customer empathy guided a major product or business decision
At the experienced level, customer-centric thinking needs to drive strategy, not just execution. Adobe asks this question to see if you can champion the customer at scale, using data and insights to influence big bets. A strong response would show how you brought forward customer evidence, influenced executives or product leaders, and ultimately shaped a decision that impacted growth or retention. This reflects Adobe’s core belief that empathy fuels innovation and long-term success.
Example: “Customer interviews revealed frustration with hidden fees. I built a case that transparency would improve retention. Leadership adopted a new pricing model, and churn dropped by 8%. This showed how empathy drives measurable business impact.”
Tip: Pair qualitative stories with quantitative impact for credibility.
How do you ensure data quality and trust across multiple source teams?
The solution starts with governance. Propose a data ownership model where each source team is accountable for schemas, SLAs, and documentation. Introduce schema enforcement, data contracts, and automated quality checks (row counts, null checks, anomaly detection). Stress the importance of a single source of truth with lineage visibility, so analysts across Adobe don’t build on conflicting metrics. Most importantly, mention the soft side: fostering a culture of accountability and regular syncs across teams. This shows you can lead not just technically but organizationally.
Example: “I implemented data contracts with ownership rules, automated anomaly alerts, and monthly syncs across data teams. This reduced conflicting metrics by 70% and improved confidence in reporting.”
Tip: Mention both technical controls and cultural practices. Adobe values both.
Describe a time you scaled a dashboard or model for global usage
Adobe is global, so scalability matters. Your answer should mention challenges like localization (multiple languages and currencies), caching for performance, role-based access controls for data security, and balancing standardization with local flexibility. For example, a global marketing dashboard might need consistent KPIs across regions while still allowing local filters for regional nuances. The trade-off discussion (speed vs flexibility, centralization vs autonomy) is key.
Example: “I built a marketing dashboard for 12 regions. To scale, I added role-based access, localization for language and currency, and caching for faster loads. Global adoption improved campaign tracking consistency while allowing regional flexibility.”
Tip: Always discuss trade-offs between standardization and customization.
Want more? Browse Adobe Data Scientist Interview Guide for targeted prep by function.
Tips When Preparing for an Adobe Interview
When you’re heading into the process, these Adobe interview preparation tips will help you stand out, both in technical problem-solving and in how you connect with Adobe’s culture and products. Unlike generic prep lists, the guidance below ties directly to Adobe’s values, products, and interview style.
Align STAR stories to Adobe’s Core Values
Adobe’s core values—Genuine, Exceptional, Innovative, Involved—are not window dressing. They show up directly in behavioral rounds. Prepare at least six STAR stories where you explicitly call out how your actions embodied these values. For example, highlight innovation by describing how you built a new framework, or involvement by recounting a cross-team initiative. A pro move: mention the value by name (“this was a time when I needed to be genuinely transparent”) to signal alignment.
Tip: Interviewers love it when candidates connect values to customer outcomes. End each story with how it improved the creator experience.
Showcase Creativity through Adobe Firefly or Creative Cloud
Few companies expect candidates to bring product demos, but Adobe does. Whether you’re applying in design, data, or engineering, consider creating a small demo, mockup, or workflow using Firefly, Photoshop, or Express. Even sketching ideas for how generative AI could expand Adobe’s ecosystem demonstrates that you’ve thought about the company’s future.
Tip: Build something personal (like re-designing your resume in InDesign or generating a custom Firefly asset) and reference it in your answer. It shows authentic engagement, not just theory.
Practice Whiteboarding System-Design or Case Questions
Adobe’s infrastructure isn’t small: millions of assets sync across devices, and products like Premiere Pro and Figma (post-acquisition) demand real-time collaboration. Practice system design questions that push beyond toy examples. Discuss trade-offs between latency and accuracy, or how you’d scale indexing for billions of creative assets.
Tip: Always frame design answers through the lens of the creator experience. For example, faster asset retrieval = less time searching, more time creating.
Benchmark Desired Adobe Levels before Negotiation
Adobe’s leveling framework (Software Engineer I → Senior → Principal → Fellow) directly ties to compensation, scope, and career trajectory. Before you walk into the process, research what level your experience aligns to. Knowing whether you’re tracking for Engineer II vs Senior Data Scientist ensures you don’t undersell yourself or misalign expectations.
Tip: Check Adobe Glassdoor reviews to see how current employees describe leveling and growth paths. It’s insider context you can reference in negotiation.
Join Adobe-specific Communities for Peer Prep
General prep on LeetCode or Interview Query will help, but Adobe candidates gain an edge from peer networks. Seek out Adobe-focused Slack, Discord, or LinkedIn groups where applicants share case questions, system design curveballs, and interview pacing.
Tip: In communities, ask specifically about values interview experiences. These are the rounds that surprise most candidates, not the coding ones.
Bring Customer Empathy into Every Answer
Adobe’s mantra is “Creativity for All.” Whether you’re writing SQL or designing a data pipeline, always link your work back to the creator. For instance, “Optimizing query speed by 20% means photographers spend less time exporting and more time editing.” This habit separates candidates who understand the tech from those who understand Adobe’s mission.
Tip: Replace “users” with “creators” in your answers. It subtly mirrors Adobe’s own language and resonates with interviewers. You can enhance your answers with a mock interview to get personalized feedback.
Demonstrate Cross-Functional Awareness
Adobe is highly matrixed: PMs, engineers, designers, and analysts work in lockstep. In your prep, think about stories that show you thrive in this environment. Did you align with engineering on feasibility? Did you tailor data insights for executives? This proves you can navigate Adobe’s cross-functional culture.
Tip: Mention specific Adobe teams (Creative Cloud, Experience Cloud, Document Cloud) when you frame cross-functional stories. It shows you’ve researched the org structure and see where you’d plug in.
Salaries at Adobe
Most data science positions fall under different position titles depending on the actual role.
From the graph we can see that on average the Product Manager role pays the most with a $159,953 base salary while the Product Analyst role on average pays the least with a $89,523 base salary.
When planning for compensation discussions, having a concrete sense of Adobe salary bands is essential. According to Levels.fyi:
- Software Engineers at Adobe in the U.S. earn between roughly $178 K (entry-level, P10) and $495 K (senior, P60), with a median total package around $308 K.
- Machine Learning Engineers command total compensation between about $234 K and $487 K, with a median near $324 K.
- The median total compensation for Product Managers is approximately $276 K, while Data Scientists average around $200K.
- Data Engineers show a regional average of about $144 K in markets like San Jose, though national or Level-based compensation may trend higher.
FAQs
What are the typical steps in the Adobe interview process?
The Adobe interview process steps usually include: a recruiter screen, an online assessment (for technical roles), 1–2 rounds of technical or case interviews, a behavioral interview focused on values, and a final hiring manager sync. Each stage assesses a combination of domain expertise, creativity, and culture fit.
How tough are Adobe behavioral interview questions?
Adobe behavioral interview questions are thoughtful and values-driven, often tied to Adobe’s pillars like Genuine and Involved. You’ll be asked to demonstrate collaboration, resilience, and customer empathy using structured STAR-format responses to real-life scenarios.
What technical areas are emphasized in Adobe interviews?
Adobe technical interview questions vary by role but frequently emphasize practical problem-solving—like SQL queries, API design, or system architecture—over purely academic puzzles. Product-facing roles often include metrics interpretation, experimentation logic, or customer impact tradeoffs.
How do Adobe levels compare to FAANG titles?
Adobe levels generally align with industry norms: Software Engineer I and II map to L3–L4 at Google, while Senior and Staff Engineers align with L5–L6. Promotion cadence is annual, with leveling tied to impact, ownership scope, and mentorship contributions.
Any quick Adobe interview preparation tips?
Top Adobe interview preparation tips include aligning STAR stories to company values, brushing up on practical case or technical problems, and reviewing Adobe’s latest product launches. Join peer prep communities and benchmark role levels before entering final negotiations.
Is it necessary to prepare for the Adobe online test?
Yes, preparation for the Adobe online test is highly recommended. The test often evaluates fundamental coding, problem-solving, or quantitative reasoning skills, depending on the role. Reviewing practice problems on platforms like HackerRank or Interview Query can boost speed and accuracy.
Does Adobe hire students or new grads?
Adobe does hire students and new graduates through university recruiting, internship programs, and entry-level roles. These opportunities are especially strong for software engineering, data science, design, and product analyst positions. Building a portfolio project or showcasing experience with Adobe tools (like Firefly or Creative Cloud) can strengthen your application.
How hard is an Adobe interview?
Adobe interviews are moderately challenging because they balance technical rigor with cultural alignment. If you are wondering, “Is it hard to get hired by Adobe?” then yes, it can be competitive, given the company’s strong brand and desirable roles. However, with structured preparation, practicing technical problem-solving, and aligning your stories to Adobe’s values, the process becomes manageable. You can practice the most common data questions on Interview Query.
Conclusion
Landing a role at Adobe means blending creativity with technical excellence—and the right prep makes all the difference.
Check out our role-specific Adobe interview guides, like Adobe Data Engineer Interview Guide and Adobe Data Scientist Interview Guide, to get tailored questions, strategy, and insights for your path.