

Google Data Scientist Interview Guide (2025) – Process, Questions & Preparation


Introduction
Every year, almost 3 million candidates apply for Google’s data science roles, and fewer than 1% make it through. It’s competitive, sure, but with the right approach, you can absolutely stand out. Google looks for data scientists who can do more than crunch numbers. They tell stories with data, design smart experiments, and build models that shape Search, YouTube, and Ads.
This guide is your roadmap to cracking one of the toughest interviews in tech, helping you master the process, anticipate the questions that matter most, and prepare with the precision and confidence it takes to land the offer.
What does a Google data scientist do?
Being a data scientist at Google is like having a front-row seat to how the internet thinks. You help decide what billions of people see, click, and experience every day. From building predictive models for YouTube recommendations to running experiments that shape Search or Ads, you turn data into stories that move products forward.
It is not a quiet, spreadsheet-only kind of job. You will collaborate with engineers, product managers, and designers, testing ideas faster than you can say “BigQuery.” Some days you are deep in Python notebooks, other days you are presenting findings that change how a product behaves worldwide.
Google’s culture thrives on curiosity and courage. People are encouraged to ask questions, take risks, and explore bold ideas. The company’s “10x thinking” philosophy pushes teams to look beyond small fixes and imagine entirely new ways to use data for good.
And while the free food and creative offices get plenty of attention, it is the shared sense of purpose that truly defines the experience. Everyone, from interns to senior scientists, works toward the same mission: to make information more useful, accessible, and meaningful through data. If you love solving problems, experimenting with ideas, and finding patterns that create real-world impact, this is where your curiosity will never run out of things to explore.
Why this role at Google
Few data science roles offer the kind of scale, challenge, and visibility that Google does. Every analysis and model can influence how billions of people search, watch, and connect daily. As a Google data scientist, you work across products like YouTube, Maps, and Ads, uncovering insights that guide product direction and improve user experience. You are not only building models but also shaping the decisions behind them. With access to world-class tools such as BigQuery, TensorFlow, and Google’s internal ML platforms, you can test ideas quickly and bring innovation to life in ways that truly move the needle.
What makes this role even more rewarding is the opportunity to grow. Google’s data science career path encourages both technical mastery and leadership development. You can advance as a senior individual contributor specializing in machine learning, experimentation, or product analytics, or move into roles that lead cross-functional teams and strategy. The company’s open culture means mentorship, rotation, and learning are part of everyday work. You are surrounded by people who question, build, and share knowledge freely, creating an environment where curiosity is fuel and growth never stops. For anyone who wants to build a meaningful, long-term career in data, Google is a place where ambition meets opportunity.
Google Data Scientist Interview Process
The Google data scientist interview process is designed to evaluate how you approach problems, translate data into insights, and collaborate in fast-moving environments. It focuses less on rote memorization and more on structured thinking, clear communication, and impact. Most candidates go through four main stages: the recruiter screen, the technical phone screen, the virtual or onsite loop, and finally, the hiring committee and offer stage.
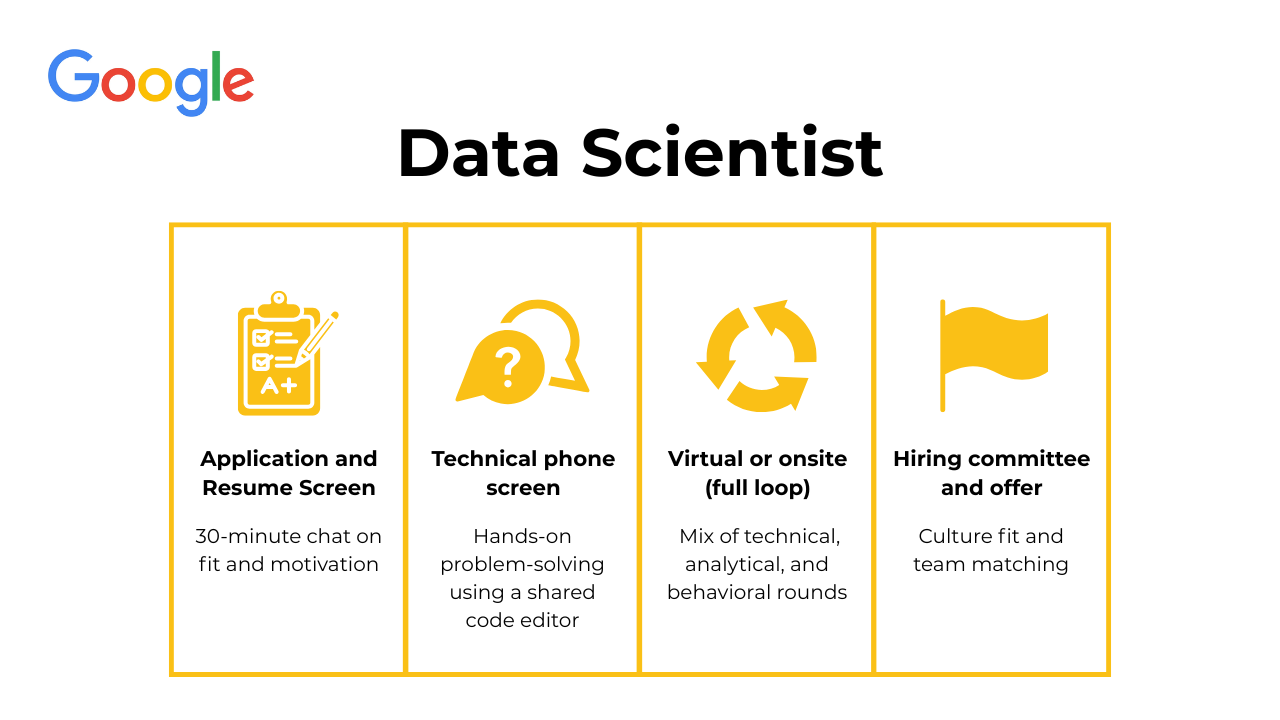
Recruiter and resume screen
This is where your application first comes to life. Recruiters look for candidates who not only meet the technical requirements but also show strong communication skills and clear motivation for joining Google. Keywords like SQL, A/B testing, machine learning, data visualization, and Python are important here. If your experience aligns, you’ll have a 25- to 30-minute introductory call where you’ll discuss your background, current projects, and why you’re interested in Google. Some candidates may receive a short pre-screening quiz to confirm technical proficiency.
Tip: Focus on storytelling. Pick one or two projects that show measurable outcomes, perhaps improving a product metric, reducing churn, or driving an A/B test that led to a feature rollout. Recruiters remember candidates who can clearly explain their work and its real-world impact.
Technical phone screen
This 45- to 60-minute interview takes place virtually through Google Meet with a shared code editor. After brief introductions, you’ll dive into a live problem-solving session that typically involves writing SQL queries or Python code to manipulate and analyze data. Expect to answer questions on algorithms, data structures, or applied statistics. You might be asked to calculate probabilities, explain when a model can or cannot be generalized, or debug code on the spot.
Tip: Treat this as a collaboration, not a test. Verbalize your logic, ask clarifying questions, and explain why you are choosing a particular approach. Google values analytical reasoning and communication just as much as correctness.
Virtual or onsite loop
This is the heart of the Google data scientist interview and typically consists of four to five interviews conducted in one day. The rounds are designed to test both technical expertise and your ability to apply data-driven thinking in real business contexts. Depending on your level, you’ll meet with data scientists, analysts, engineers, and product managers.
Coding interview
You’ll be asked to write efficient and clean code using Python or SQL. Questions often involve manipulating large datasets, merging tables, calculating metrics, or performing simulations. Efficiency, readability, and correctness all matter.
Tip: Start by outlining your plan before you begin coding. Once you’ve finished, walk through your logic step by step and check for edge cases. Interviewers appreciate clarity and structured reasoning.
Statistics and experimentation interview
This round tests your grasp of hypothesis testing, experiment design, and causal inference. You might be asked to design an A/B test for a new YouTube feature or explain how you’d measure the success of a change in Google Maps. You’ll need to balance statistical rigor with business practicality.
Tip: Frame your answers using the scientific method. Define the problem, describe your hypothesis, identify metrics, and explain how you’d interpret results. Always mention how you would handle confounding variables and ensure test reliability.
Machine learning or applied modeling interview
For candidates applying to product or research-focused roles, this round evaluates your understanding of model selection, overfitting, and performance evaluation. You may need to explain how you’d build or optimize a model for a specific use case, such as predicting ad click-through rates or ranking search results.
Tip: Focus on trade-offs. Explain when you’d favor a simple model for interpretability versus a complex one for performance. Showing that you understand real-world constraints will earn extra points.
Product or business sense interview
This round tests how you connect data to decisions. Expect open-ended questions about metrics, user behavior, and product strategy. For example, you might be asked how to evaluate the impact of a new recommendation system or what data you’d track to improve user engagement.
Tip: Think like a product owner. Start with the goal, explain the metric that reflects it, and describe how you’d measure success over time. Google interviewers value candidates who understand not just how to analyze data, but why it matters.
Behavioral interview
The final interview in the loop focuses on collaboration, adaptability, and “Googleyness.” Interviewers may ask how you resolved a conflict, handled project ambiguity, or worked under tight deadlines. They want to see how you communicate, manage feedback, and approach teamwork.
Tip: Use the STAR method (Situation, Task, Action, Result) to structure your stories. Choose examples that highlight ownership, creativity, and learning. Keep your answers authentic and outcome-oriented.
Hiring committee and offer
Once you finish the virtual or onsite loop, the interviewers submit detailed feedback on your performance. These notes are compiled into a candidate packet, which includes your scores, resume, and interview summaries. This packet then goes to a separate hiring committee composed of senior Googlers who were not part of your interviews. Their job is to ensure fairness, consistency, and quality across all data science hires. The committee reviews your strengths, assesses cultural and technical fit, and decides whether to move you forward.
If you are approved, you enter the team matching phase. This stage often feels like the final stretch but it is still a crucial part of the process. You will meet with potential managers from different teams to find the right fit for your background and interests. These conversations are more exploratory than evaluative. You will discuss what the team is currently building, the challenges they face, and how your skills can help. It is perfectly fine to ask thoughtful questions about the tech stack, product roadmap, or culture to ensure the role aligns with your goals.
Once you have matched with a team, your recruiter will prepare a formal offer. This typically includes your base salary, annual bonus target, and restricted stock units (RSUs). Google is known for its strong total compensation packages, and equity can form a significant portion of your long-term rewards. You will receive a detailed breakdown of your compensation structure and may have a chance to review it before responding.
Tip: Treat negotiation as a conversation, not a confrontation. Express excitement about the opportunity and gratitude for the offer before discussing adjustments. Research current data scientist salary benchmarks using sites like Levels.fyi so you can make informed requests. Focus on total compensation rather than base salary alone, and be clear about what matters most to you, whether it is equity, relocation support, or start date flexibility. Recruiters are often open to discussions, especially when you can provide data and context to back your request.
Need 1:1 guidance on your interview strategy? Interview Query’s Coaching Program pairs you with mentors to refine your prep and build confidence. Explore coaching options →
Google Data Scientist Interview Questions
Google data scientist interview questions go beyond technical accuracy. They are designed to see how you reason, organize your thoughts, and make decisions under time pressure. Your ability to communicate your process often matters more than getting every detail perfect. Below are the main categories of questions and how to approach them strategically.
Coding interview questions
These are the backbone of the Google data scientist interview. You will face questions that test your fluency in SQL and Python, your ability to manipulate data efficiently, and your comfort with statistics. The goal is to see how you transform data into insight, not just how quickly you can code. Interviewers want to understand how you think through data problems, whether you can work with imperfect information, and how you explain your approach clearly. Expect scenarios that simulate real data challenges, such as filtering users, aggregating transactions, and interpreting metrics. Treat these rounds as your chance to show that you are not only technically capable but also structured and thoughtful in problem solving.
How would you combine two datasets to create complete addresses for each record?
This question assesses how you join tables and ensure data completeness. You are given one table with partial address details and another that maps city-state relationships. The task is to merge them into a single, accurate dataset that includes city, state, and zip code information. Start by identifying the best key to join on, such as city ID, and consider how to handle cases where records are missing or mismatched. You should think aloud about whether to use an INNER or LEFT JOIN, depending on whether incomplete addresses should still appear. Strong answers demonstrate awareness of both logic and data quality considerations.
Tip: Always confirm the uniqueness of your join keys before combining tables to avoid duplication and inflated results.
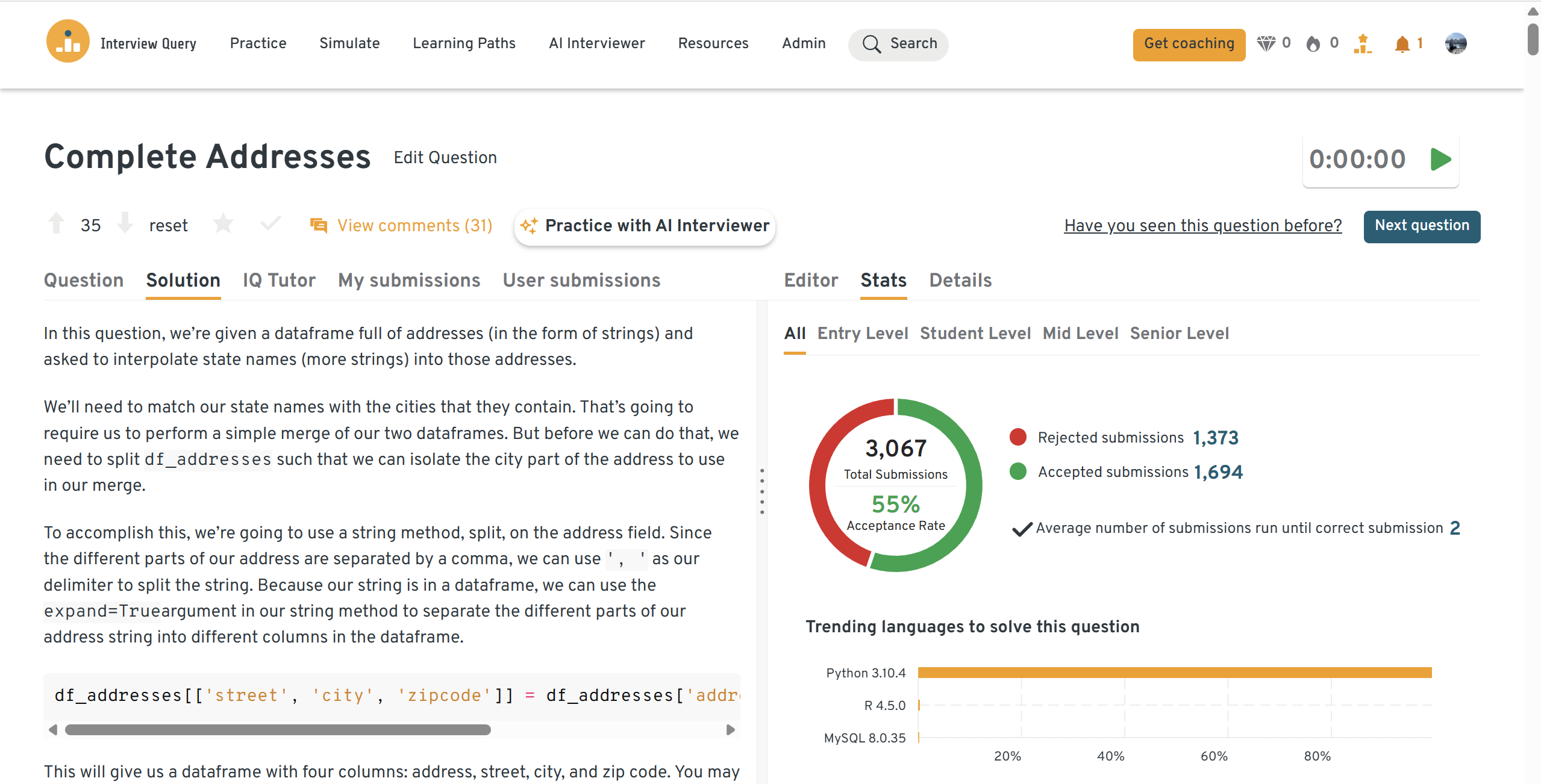
You can practice this exact problem on the Interview Query dashboard, shown below. The platform lets you write and test SQL queries, view accepted solutions, and compare your performance with thousands of other learners. Features like AI coaching, submission stats, and language breakdowns help you identify areas to improve and prepare more effectively for data interviews at scale.
How can you write a SQL query to find the second-highest salary in the engineering department?
This question checks how you approach ranking and filtering within grouped data. Begin by partitioning the data by department and ordering salaries in descending order using a function such as
DENSE_RANK()orROW_NUMBER(). Then, filter for the rank that corresponds to the second-highest value. Be ready to explain what happens if multiple employees share the top salary or if a department has only one employee. This is less about memorizing syntax and more about showing that you understand the logic behind ranking and fairness in results. Clarity in your explanation is key.Tip: Compare
RANK()andDENSE_RANK()as you explain your reasoning. Showing that you know how each handles ties will make your answer stronger.-
This question tests your understanding of attribution logic and your ability to connect data tables meaningfully. You will have one table logging session visits and another linking users to those sessions. Start by filtering for users who converted, then find the earliest session timestamp per user. Once you have that, return the associated marketing channel for the first session. As you explain, discuss how you would validate this by stepping through a single user’s timeline to confirm that your query produces the expected result. The goal is to show both technical accuracy and business understanding.
Tip: Walk through one example user during your explanation. It helps interviewers see that you can reason through results, not just write code.
How would you find the top three highest salaries in each department?
This question measures your comfort with SQL ranking functions and edge case handling. Begin by partitioning your data by department and ordering employees by salary in descending order. Use
DENSE_RANK()orROW_NUMBER()to assign ranks, then filter for ranks less than or equal to three. Sort by department name and salary to make the output clear. Mention that your logic still works for departments with fewer than three employees, as that kind of defensive thinking impresses interviewers. Good answers combine concise code with careful explanation.Tip: Always explain how your query handles ties in salary. It shows you anticipate data complexities that could affect the results.
How would you get the last transaction for each day from a bank transactions table?
This question tests your ability to apply ordering logic using time-based data. You can use
ROW_NUMBER()orRANK()to partition transactions by date and order them by timestamp in descending order. Selecting the top record per partition gives you the most recent transaction of each day. Alternatively, you can use a subquery that finds the maximum timestamp per day and join it back to the main table. Explain both methods and discuss when you would use one over the other. Strong candidates mention performance and readability when justifying their approach.Tip: Briefly discuss how large datasets might influence your choice between window functions and subqueries. Awareness of scalability stands out at Google.
-
This question evaluates your conceptual understanding of joins and how data relationships affect output size. You are asked to calculate how many rows result from INNER, LEFT, RIGHT, and CROSS joins between a main table and a subquery of top ads. To solve this, you need to reason through the logic of each join type: INNER joins return matches, LEFT joins include all left rows with possible nulls, RIGHT joins preserve the right table, and CROSS joins multiply all combinations. Instead of jumping to an answer, explain how you’d test this conceptually or with small datasets. The interviewer wants to hear your reasoning, not just definitions.
Tip: Think visually. Sketching out how each join type behaves or explaining it with examples shows mastery and confidence.
Product and experimentation interview questions
These questions measure how well you connect data insights to business strategy. Google wants to see that you can translate analysis into real impact, not just build dashboards. You will often be asked to evaluate product features, design A/B tests, or define key metrics. Interviewers are looking for structured thinking, clear trade-off reasoning, and curiosity about user behavior. Imagine you are a product scientist sitting next to a product manager deciding whether to launch a feature. Your goal is to show that you understand both the data and the decision behind it.
1. How would you assess the validity of an A/B test result that shows a 0.04 p-value?
Begin by restating what a p-value means in the context of an A/B test: a 0.04 p-value indicates that there is a 4 percent chance the observed result happened by random variation under the null hypothesis. Next, discuss whether the test met the assumptions required for the p-value to be valid, such as random sampling, independence, and proper traffic allocation. You should also confirm that multiple comparisons or early peeking at results did not inflate false positives. Consider whether the effect size is practically significant, not just statistically significant. If the uplift is small, even a low p-value may not justify rolling out the change. Finally, mention how you would replicate or validate the finding through a follow-up experiment.
Tip: Always separate statistical significance from business significance. Google interviewers want to see that you interpret numbers in context, not in isolation.
2. In an A/B test, how would you verify that users were assigned to test buckets randomly?
Start by explaining that proper randomization is critical to experiment validity. To check it, you would first compare baseline metrics between control and treatment groups, such as average session count or user demographics, before the experiment begins. Small differences are expected, but large ones may indicate bias or a technical issue in the assignment logic. You can also run a chi-square test or t-test on pre-experiment metrics to ensure there are no statistically significant differences between groups. Beyond numbers, describe how you might audit the randomization script or system to verify that hashing or bucketing was implemented correctly. Close by emphasizing that detecting bias early saves teams from drawing incorrect conclusions later.
Tip: Mention that you would visualize pre-test data distributions. Visual checks often catch assignment issues that summary statistics alone can miss.
This question explores your ability to handle multi-factor testing. Begin by explaining that because there are two independent variables (color and placement), a factorial design is ideal. You could create four variations: red-top, red-bottom, blue-top, and blue-bottom. This allows you to measure both the individual and interaction effects of color and placement. Describe how you would define your primary metric, such as click-through rate, and calculate how much traffic is needed to achieve statistical power for multiple groups. Finally, mention how you would use post-experiment analysis to determine which factor had the stronger influence.
Tip: Always state your hypothesis before running a multivariate test. This shows that your experimentation process is structured and intentional.
Start by recognizing that many real-world metrics are skewed, especially when sample sizes are small. Explain that standard t-tests assume normality, so you would switch to non-parametric alternatives like the Mann–Whitney U test or bootstrapping methods. Walk through how these approaches compare distributions without relying on the mean alone. Discuss that you would also visualize data to understand the nature of skewness and confirm whether outliers are influencing results. Then, explain how you would report median values or percentiles to communicate performance more accurately. Finally, note that small sample experiments require extra caution and often benefit from Bayesian approaches that can handle uncertainty better.
Tip: Mention that you would complement statistical tests with practical significance. A variant that wins by a tiny margin might not justify deployment.
5. How would you write a function that automatically generates a histogram from a dataset?
This question tests how you translate statistical thinking into code. You are asked to create a function that divides a dataset into uniform bins and counts the number of elements in each. Start by finding the range of the dataset and dividing it into equal intervals. Then, iterate through each element, identify which bin it belongs to, and increment the count for that bin. You should also handle edge cases such as empty bins or datasets with very few unique values. When explaining your logic, focus on clarity, variable naming, and code readability rather than syntax memorization.
Tip: Explain how you would choose the number of bins dynamically. Mentioning techniques like Sturges’ rule or the square root method shows depth in your reasoning.
Machine learning and research interview questions
Machine learning and research questions usually appear in technically specialized or research-oriented data science roles at Google. For product or business-focused positions, expect these questions to stay conceptual rather than mathematical. The goal is to see if you understand model behavior, performance trade-offs, and how algorithms scale in production. Interviewers want to know that you can reason through why a model works, when it might fail, and how to make it more reliable. Even if you are not writing code, demonstrating structured thinking and practical intuition about machine learning can help you stand out.
1. When should you use regularization versus cross-validation?
This question tests whether you understand the purpose of each technique and when to apply them. Regularization is used to reduce overfitting by penalizing model complexity, which helps keep weights small and improves generalization. Cross-validation, on the other hand, is a method for evaluating model performance on unseen data to prevent over-optimistic results. You would typically use regularization during model training and cross-validation when tuning hyperparameters or comparing model variants. In your answer, explain that these techniques complement each other rather than compete. They are both tools to ensure your model performs well outside of training data.
Tip: Frame your answer with a simple sequence: regularization controls model complexity, cross-validation measures generalization. Linking the two clearly will show a strong grasp of ML fundamentals.
Start by noting that randomness is built into many ML algorithms. Variations in random seed initialization, data shuffling, or batch ordering can change model performance slightly each time you train it. You can also discuss factors such as hyperparameter tuning, convergence criteria, and differences in hardware precision that might produce small numerical variations. A good answer also highlights overfitting and data leakage as potential hidden causes of performance discrepancies. Finally, emphasize reproducibility as a best practice by setting seeds, logging configurations, and versioning data and code. This demonstrates awareness of how to manage experimentation rigorously.
Tip: Always connect the explanation back to experimentation discipline. Google values data scientists who know how to build reproducible and trustworthy results.
3. How would you design the YouTube video recommendation algorithm?
This question evaluates your ability to reason about large-scale personalization systems. Start by outlining the overall flow: data collection, feature extraction, candidate generation, ranking, and feedback loops. Explain that you would use collaborative filtering or deep learning models to predict engagement likelihood while balancing freshness, diversity, and user safety. Discuss how you would incorporate user watch history, content metadata, and contextual signals like time of day. Then, describe how you would evaluate the system using metrics such as watch time, click-through rate, and satisfaction surveys. Mentioning how you would guard against filter bubbles or bias shows strong ethical awareness.
Tip: Tie your answer to impact. Show that you understand recommendation models as both technical systems and user experience engines.
4. How would you build the recommendation algorithm for type-ahead search for Netflix?
This question explores how you apply machine learning to improve search relevance and latency. Begin by explaining that type-ahead search predicts user intent as characters are typed. You would use historical query logs, embeddings, and user behavior data to rank potential completions in real time. Describe how you would deploy a hybrid model that combines prefix-based lookup with ranking models trained on engagement metrics like click-through rate. Be sure to emphasize scalability and speed, since these systems must respond in milliseconds. Conclude by explaining how you would evaluate performance through A/B testing and offline relevance metrics such as precision at K.
Tip: Highlight trade-offs between speed and personalization. Google looks for candidates who can balance model performance with user experience.
5. How can you prove that a k-means clustering algorithm converges in a finite number of steps?
This question checks your theoretical understanding of clustering algorithms. Start by recalling that k-means alternates between two operations: assigning points to the nearest centroid and updating centroids based on those assignments. Each iteration reduces the total within-cluster variance, which is a non-negative quantity. Because the number of possible cluster assignments is finite, the algorithm must eventually reach a state where no further reduction is possible. That point is convergence, even if it is only to a local minimum. In your explanation, focus on logical reasoning rather than formal proofs, showing that you understand why the algorithm stabilizes naturally.
Tip: Keep your explanation intuitive. Use simple language that shows conceptual clarity rather than relying on heavy mathematical proofs.
Behavioral and communication questions
Behavioral questions reveal how you think, collaborate, and navigate challenges. Google values self-awareness, curiosity, and structured communication. Interviewers want to see that you can reflect on your experiences, draw lessons from them, and connect them to how you work today. Use the STAR method (Situation, Task, Action, Result) to organize your answers clearly. Focus on measurable outcomes and what you learned.
1. Describe a data project you worked on. What were some of the challenges you faced?
This question is about how you handle complexity and problem-solving in real-world projects. The interviewer wants to hear about technical and communication hurdles and how you adapted to overcome them. When answering, pick a project with clear stakes and multiple moving parts such as data quality issues, stakeholder alignment, or limited resources. Explain how you identified the bottlenecks, what steps you took to resolve them, and what impact your solution had. End by highlighting what you learned that made you more effective in later projects.
Sample Answer: I once led an internal analytics project that aimed to automate weekly marketing reports. The data sources were inconsistent, and our ETL pipeline kept breaking mid-run. I collaborated with engineering to redesign the data validation logic and set up alerting thresholds. As a result, our error rate dropped by 70 percent, and the marketing team received reports on time every week. The experience taught me the importance of building redundancy and monitoring early, not after launch.
2. What are some effective ways to make data more accessible to non-technical people?
Here, the interviewer is looking for communication and empathy skills. Data scientists at Google often present to product managers, designers, or executives who may not have a technical background. Focus on strategies that bridge the gap between raw data and actionable insights. Examples include using intuitive dashboards, simple visualizations, or clear narratives that tie metrics to outcomes. Mention how you tailor your message based on your audience’s familiarity with the topic.
Sample Answer: In one cross-functional project, I noticed that business stakeholders were struggling to interpret our retention metrics. I created an interactive dashboard in Data Studio that summarized results visually and added short explanations for each key metric. I also held quick walkthrough sessions to answer questions and collect feedback. After these changes, the leadership team started referencing the dashboard during weekly meetings instead of waiting for analyst reports. It made decision-making faster and built trust in our data process.
3. What would your current manager say about you? What are your biggest strengths and weaknesses?
This question measures self-awareness and growth mindset. A strong answer shows that you know your strengths, can back them up with evidence, and are proactive about improving your weaknesses. Avoid vague responses like “I’m a perfectionist.” Instead, give specific examples of how you developed your strengths and how you are working on your weaker areas. Remember that Google values learning over perfection, so frame weaknesses as ongoing improvements.
Sample Answer: My manager would say I’m consistent and dependable when tackling complex problems. I’m strongest at building structure out of messy datasets and communicating my findings clearly. One area I’ve worked on is delegating early instead of doing too much myself. Over the past few projects, I’ve made it a habit to outline responsibilities with teammates upfront, which has improved both my workflow and our team’s efficiency.
This question evaluates your communication maturity and adaptability. Interviewers want to see that you can handle misunderstandings diplomatically and adjust your approach when needed. Start by describing the context: who the stakeholders were and why miscommunication happened. Then explain how you clarified expectations, realigned goals, or used data to rebuild trust. End with what changed as a result of your actions.
Sample Answer: During a product launch, a project manager misinterpreted our retention metrics and thought the feature was underperforming. Instead of debating, I scheduled a short session to walk through the metric definitions and explained how early churn was expected based on user segmentation. We agreed to reframe the KPIs around long-term engagement instead. This shifted the conversation from blame to action, and the feature ended up exceeding retention targets within the next quarter.
5. Why do you want to work at Google, and what makes you a strong fit for the team?
Google interviewers use this question to test motivation and alignment. They want to know that you’ve done your research and can articulate why the company’s mission or culture excites you. Avoid generic answers about innovation or scale. Instead, reference a product, team, or principle that genuinely resonates with you and link it to your skills or values. This question is also your chance to show enthusiasm without overselling.
Sample Answer: I’ve always admired Google’s commitment to solving problems through data at scale, especially in Search and sustainability initiatives. I’m drawn to the company’s collaborative culture and its openness to experimentation. My background in experimentation design and statistical modeling aligns closely with how Google approaches data-driven decision-making. I’m excited by the opportunity to work on systems that reach billions of users while still prioritizing fairness and accuracy in insights.
6. Tell me about a time you influenced a product or business decision using data.
This question focuses on impact. Interviewers want to know how you move from analysis to action and how you persuade others to adopt your recommendations. Start by describing the problem and the decision at stake, then outline how you gathered and analyzed data. Explain how you communicated your findings and what the outcome was. Close with how the experience shaped your approach to stakeholder communication or analytical rigor.
Sample Answer: I once analyzed the onboarding funnel for a mobile app and discovered that 30 percent of users dropped off at a permissions screen. I quantified the impact and proposed a simple UX fix: delaying the prompt until users completed the first task. After implementing the change, activation rates rose by 18 percent. It reinforced how small, data-driven adjustments can significantly improve user experience and retention.
7. Describe a time when you had to make a decision with incomplete data.
Google uses this question to assess judgment and confidence under uncertainty. Data scientists rarely have perfect information, so the interviewer wants to see how you make reasoned decisions with limited evidence. Emphasize your ability to identify assumptions, weigh risks, and validate your choice later through follow-up analysis. This demonstrates both analytical thinking and accountability.
Sample Answer: While working on pricing experiments for a subscription feature, I had incomplete data due to tracking gaps. I estimated demand elasticity using comparable regions and modeled the expected revenue impact under different pricing tiers. I presented my findings with confidence intervals to show uncertainty. We launched a limited rollout using my midrange estimate, and the results closely matched projections. This taught me how to balance analytical rigor with timely decision-making.
How To Prepare for Google Data Scientist Interview
Getting ready for a Google data scientist interview is not just about grinding SQL problems or reviewing A/B testing theory. It is about thinking like a Googler: curious, structured, and impact-driven. The best preparation balances technical skill, storytelling, and clear thinking. Here is how you can prepare smartly and stand out from the crowd.
Master SQL under pressure
SQL at Google is everywhere, from quick ad hoc analysis to complex feature evaluation. The questions go beyond syntax and test whether you can reason through data while explaining your thought process. You might need to join large datasets, design ranking logic, or handle tricky filtering conditions. Practice solving problems out loud, keeping your code clean and your logic simple. Clarity always beats cleverness.
Mini Tip: Treat each query like a conversation with the data. Ask a clear question, listen carefully to the answer, and adjust if needed.
Get experimental with your thinking
Google loves people who can think like scientists. You will be asked about experiment design, p-values, and how to draw conclusions even when data is noisy. More than formulas, interviewers care about how you make testing decisions, define success, and communicate uncertainty. Be ready to discuss trade-offs between speed and rigor or what you would do if an A/B test result is inconclusive. Bringing real examples helps make your answers sound authentic and grounded.
Mini Tip: Pick a favorite Google product, imagine a new feature, and design a quick A/B test for it. Thinking this way trains your intuition for experimentation.
Think like a product strategist
At Google, data scientists influence products, not just spreadsheets. Expect questions about defining success metrics, identifying key user behaviors, and prioritizing trade-offs. The best answers show that you understand both the data and the decision behind it. Tie your analysis to user experience, business outcomes, and long-term growth. Remember that interviewers are listening for structure and curiosity, not buzzwords.
Mini Tip: When using a Google product, ask yourself, “What metric defines success here?” Building that habit strengthens your product sense.
Make your insights unforgettable
Numbers do not speak for themselves. You have to tell the story. Google values data scientists who can turn technical findings into persuasive insights. Practice summarizing complex analyses in plain language, using visuals or examples when helpful. If you can make a VP understand why your model matters in one sentence, you are doing it right.
Mini Tip: Explain your last project to a friend who works outside tech. If they understand it and stay interested, your storytelling is on point.
Know your machine learning fundamentals
While not every role requires deep ML implementation, you should understand the intuition behind key models. Be ready to explain concepts like overfitting, regularization, and model interpretability. Google often tests whether you can reason about model choice rather than derive equations. Show that you know how to apply theory to real data problems and when to prioritize simplicity over complexity.
Mini Tip: Instead of memorizing formulas, focus on explaining “why this model” in each scenario. That is what separates thoughtful analysts from memorization machines.
Do your homework on Google’s data culture
Every Google team approaches data a little differently, but they all share one thing: scale. Read Google AI Blog articles, research papers, or engineering posts to understand how they handle fairness, experimentation, and personalization. If you can connect your answers to how Google actually operates, your responses will feel informed and credible.
Mini Tip: Before your interview, pick one Google product you admire and outline how you would measure its success. Bringing this up naturally in conversation can leave a strong impression.
Tell stories that show real impact
Behavioral questions are your chance to shine as more than a statistician. Talk about projects where your insights made a measurable difference. Use the STAR method to explain the situation, what you did, and what changed as a result. Be specific about the outcomes, whether that is a conversion lift, faster decision-making, or a smoother workflow. Interviewers remember impact and reflection more than jargon.
Mini Tip: End every story with a lesson learned. It shows humility, growth, and the kind of mindset Google values.
Practice like it is the real thing
There is no substitute for simulation. Practice full-length mock interviews with peers or mentors where you code, think aloud, and answer follow-ups on the spot. Use a shared document or whiteboard tool to mimic the real setup. The goal is not just accuracy but fluency — how well you can explain your thinking under time pressure.
Mini Tip: Recreate the real interview environment, timer and all. Familiarity builds confidence faster than repetition.
Want to practice real case studies with expert interviewers? Try Interview Query’s Mock Interviews for hands-on feedback and interview prep. Book a mock interview →
After all that prep talk, you might want to see how it all comes together in action. This video features Jay Feng, co-founder of Interview Query, breaking down the Google data scientist interview process and how data scientists work across different teams, products, and features. Watch as he explains the types of questions you’ll face, how Google evaluates analytical thinking and communication, and what successful candidates do differently. It’s a short, practical recap that helps you visualize what success looks like.
Now that you’ve got the big picture, let’s look at what makes Google’s data scientist roles even more attractive: the compensation.
Average Google Data Scientist Salary
Google data scientists in the United States earn some of the most competitive compensation packages in the tech industry. According to Levels.fyi data, total annual pay ranges from around $168K per year for L3 (Data Scientist II) to $900K per year for L8 (Principal Data Scientist). The median total compensation across levels is approximately $348K annually.
- L3 (Data Scientist II): $168K per year ($132K base + $20K stock + $7K bonus)
- L4 (Data Scientist III): $264K per year ($180K base + $66K stock + $24K bonus)
- L5 (Senior Data Scientist): $372K per year ($204K base + $120K stock + $36K bonus)
- L6 (Staff Data Scientist): $444K per year ($240K base + $156K stock + $49K bonus)
- L7 (Senior Staff Data Scientist): $696K per year ($288K base + $360K stock + $62K bonus)
- L8 (Principal Data Scientist): $900K per year ($348K base + $468K stock + $81K bonus)
Compensation for Google data scientists varies by location due to cost-of-living adjustments and market competition.
- San Francisco Bay Area: Median total compensation is around $360K per year, with stock contributing heavily to long-term rewards. (Levels.fyi)
- New York City Area: Packages average $288K annually, slightly below Bay Area levels but often balanced by smaller commute costs. (Levels.fyi)
- Greater Seattle Area: Average total compensation is around $312K per year, with high stock value growth potential. (Levels.fyi)
- Greater Los Angeles Area: Median total compensation is approximately $252K per year, reflecting a mix of steady base and smaller stock packages. (Levels.fyi)
- Greater Chicago Area: Typical total compensation is around $228K per year, lower than coastal hubs but still well above the national average. (Levels.fyi)
Average Base Salary
Average Total Compensation
Google’s compensation structure balances stability with long-term incentive. A high base salary ensures consistency, while equity grants and annual bonuses reward performance and company growth. Stock typically accounts for 25–40% of total pay, making Google data scientist roles especially lucrative for long-term employees.
FAQs
What does a Google data scientist do?
A Google data scientist turns billions of data points into insights that drive smarter decisions. They help shape everything from how YouTube recommends videos to how Search results are ranked. The work combines statistics, product strategy, and storytelling to improve products used by billions every day.
What is the Google data scientist interview process?
The process typically starts with a recruiter call, followed by one or two technical screens and a full virtual onsite. You will go through rounds that test SQL, statistics, product sense, and communication. The final step is a hiring committee review and team-matching process, where your fit is evaluated based on skills and interests.
How hard is it to get into Google as a data scientist?
Getting into Google as a data scientist is extremely competitive. With millions of applicants every year and an acceptance rate below 1%, the bar is high. Candidates who succeed typically demonstrate strong technical foundations, clear communication, and the ability to connect their analyses to real-world product impact. Consistent practice and familiarity with Google’s data-driven culture are key to standing out.
What data scientist skills does Google look for?
Google looks for a mix of technical depth and product intuition. Strong SQL, statistics, and experiment design skills are a must, along with the ability to translate findings into business or product impact. Clear communication and collaboration are just as important as analytical ability.
How long does the Google hiring process take?
The Google data scientist hiring process usually takes between three and six weeks. Timing depends on how quickly interviews are scheduled and how long team matching takes. Staying in touch with your recruiter is the best way to keep things moving.
Does every Google data scientist interview include machine learning questions?
Not always. ML questions are more common for research or technical data science roles, while product and analytics tracks focus on experimentation, metrics, and SQL. Still, having a solid grasp of model basics helps show well-rounded understanding.
How can I make my data science resume stand out for Google?
Keep it impact-driven. Highlight how your analysis or projects led to measurable results, and mention the tools or frameworks you used. Recruiters scan fast, so focus on clarity, numbers, and achievements that show scale.
How much coding is expected in the Google data scientist interview?
You should be comfortable writing SQL queries and simple Python or R code to clean, analyze, and visualize data. The goal is not to write perfect syntax but to show clear logic and problem-solving ability. Explaining your thought process while coding is key.
What is “Googleyness,” and how does it affect the interview?
Googleyness means being curious, collaborative, and adaptable. It is about showing humility, empathy, and the drive to keep learning. Interviewers look for candidates who bring both analytical sharpness and genuine teamwork energy to the table.
How can I prepare in the final few days before the interview?
Spend time refining your storytelling and problem-solving flow. Review SQL joins, experiment design, and practice explaining your answers out loud. Most importantly, relax and focus on being clear and confident. Google interviews reward structured thinking, not memorization.
How much does Google pay a data scientist?
According to Levels.fyi, total compensation for Google data scientists in the United States typically ranges from $168K for entry-level roles (L3) to over $900K for senior and principal levels (L8). Packages include base salary, annual bonuses, and stock grants, which can significantly increase total earnings over time.
Start Your Google Data Scientist Interview Prep Today!
The Google data scientist interview is one of the most exciting opportunities in tech. It challenges you to combine analytical rigor, creativity, and clear communication to solve problems that influence billions of users. Whether you are analyzing experiments, modeling trends, or shaping product metrics, this role rewards structured thinkers who can turn data into meaningful impact.
Begin your prep journey with tools designed to help you succeed. Practice real Google data scientist interview questions, book a mock interview to get feedback from experienced mentors, or follow the data science learning path to sharpen your technical and product sense. Every problem you solve brings you one step closer to landing your dream role at Google.