

Weighted Average in SQL Guide (Updated for 2025)

Overview
Data analysis plays a pivotal role in decision-making processes across various industries. Among the many techniques available, the weighted average is a powerful tool for deriving valuable insights from numerical data. But how exactly can we calculate the weighted average using SQL?
Let’s explore some practical tips and techniques for generating the weighted average using SQL.
What Is Weighted Average in SQL?
What is the weighted average, and how does it differ from the arithmetic mean?
The rationale behind the arithmetic mean is simple– it represents a set of data points as a singular output. There are limitations to this approach since it assumes that all data points are of equal importance, which isn’t always the case in the real world. To accommodate for variance in significance or “weights”, we use the weighted average.
The general query for the weighted average is:
SELECT (SUM(value * weight) / SUM(weight))
Figure 1.1: The General Form for the Weighted Average
This query represents the weighted average formula, which calculates the weighted average by dividing the total sum of the products of each value (valueᵢ) and its corresponding weight (weightᵢ) by the sum of all the weights (weight_j).
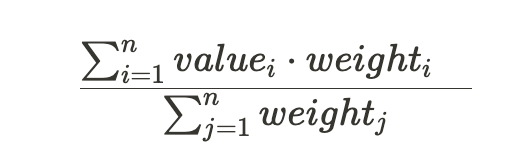
Figure 1.0: Formula for the Weighted Average (assuming non-percentile weights)
We can see that the formula above maps to our SQL query straightforwardly. SUM(value * weight) corresponds to the numerator, while SUM(weight) is the denominator of the formula.
It seems simple, right? However, while this general formula is technically the correct answer, not all applications of weighted averages will reflect this general form. To learn how to deal with real-world schemas, let’s take a look at some different examples.
SQL Weighted Average Example with Real-World Schemas
The general query for the weighted average (Figure 1.1) assumes that we’re gathering the weighted average for the whole table. However, data scientists and analysts typically use databases with more complex schemas in their day-to-day workflow.
To see how we can adjust the general query, we’ll use the following table schemas to set up a more realistic example.
Students table
| Column | Data Type |
|---|---|
| student_id | INT (PK) |
| student_name | VARCHAR(50) |
Grades table
| Column | Data Type |
|---|---|
| grade_id | INT (PK) |
| student_id | INT (FK) |
| course_name | VARCHAR(50) |
| grade | DECIMAL(3,2) |
| units | INT |
Let’s assume that you’re working as a data analyst for a university. You’re tasked to generate a report on the general weighted grade point average (GWA) of all the students in the university. Since courses have different weights (represented in this case as units), it’s important to use the weighted average instead of the arithmetic mean to calculate the final output.
Since we need to generate the weighted average per student with our table schema, the general form solution by itself won’t work for this problem.
The grades table has a many-to-one relationship with the Students table, and we can map many grades to one student. To generate one GWA for each student, we can use GROUP BY and SUM, which is the first approach we’ll discuss today.
Approach 1: GROUP BY and SUM
The many-to-one nature of our schema makes GROUP BY a natural choice for our solution. From the general form, our query will transform into:
SELECT
students.student_name,
SUM(grades.units) AS 'Total Units Taken',
ROUND(SUM(grades.grade * grades.units) / SUM(grades.units), 3) AS 'General Weighted Average'
FROM
grades
INNER JOIN
students ON grades.student_id = students.student_id
GROUP BY
grades.student_id;
Figure 2.0: GROUP BY and SUM Solution
While this looks very different from the general form presented above, the line ROUND(SUM(grades.grade * grades.units) / SUM(grades.units), 3) AS 'General Weighted Average' is just a modified version of our basic query.
In the next section, we’ll break down our solution in parts to show how we generated this example.
If you need a refresher on the basics of GROUP BY, read through the Interview Query Introduction to SQL course.
GROUP BY with the General Form
General Weighted Average
Using the table schema, a grade can be mapped to a student using the foreign key, which in this case is student_id.
| student_id | student_name | course_name | grade |
|---|---|---|---|
| 1 | John Smith | Mathematics | 3.50 |
| 1 | John Smith | Physics | 4.00 |
| 1 | John Smith | English | 3.80 |
| 2 | Jane Doe | Chemistry | 3.90 |
| 2 | Jane Doe | Biology | 3.70 |
Figure 2.1: Table before GROUP BY
To work with the data more efficiently, we’ll use the GROUP BY clause on the grades.student_id column.
This will group rows with the same student_id, effectively dividing the original table into smaller sets of data. We can then perform the operations in the general form on each set separately, rather than on the entire table.
| student_id | student_name | course_name | grade |
|---|---|---|---|
| 1 | John Smith | Mathematics | 3.50 |
| 1 | John Smith | Physics | 4.00 |
| 1 | John Smith | English | 3.80 |
| student_id | student_name | course_name | grade |
|---|---|---|---|
| 2 | Jane Doe | Chemistry | 3.90 |
| 2 | Jane Doe | Biology | 3.70 |
Figure 2.2: Tables after GROUP BY
We can now treat grades.grade as the value and the grades.units as the weight. The joins are then done to match a student name to a GWA. Using the general form (with GROUP BY, of course), our output will be:
| student_name | Total Units Taken | General Weighted Average |
|---|---|---|
| John Smith | 10 | 3.740 |
| Jane Doe | 7 | 3.814 |
| Michael Johnson | 7 | 3.371 |
| Emily Williams | 6 | 3.667 |
| Daniel Brown | 6 | 3.700 |
| Olivia Davis | 4 | 3.400 |
Figure 2.3: Results of the GROUP BY and SUM Query
Approach 2: Window Functions and the Weighted Moving Average
Our first approach is great whenever we want something as simple as a general weighted average. But, if we want our data to be dynamic (such as in leaderboards or scoreboards), a moving average may be more suitable. Using our previous table schema, how could we get the moving weighted average with SQL?
Because our values now vary based on previous data (as the data is moving), we’ll need to employ a more advanced SQL feature called window functions. This will allow us to aggregate data on a per-row (or per window) basis instead of by table. While we tackled the first iteration of breaking down the table with GROUP BY, we can create a more granular solution using window functions.
Window Functions
Window functions are functions that use one or multiple rows to return values for each row. They are different from aggregate functions in that aggregate functions return just one value for every group of rows, while window functions return a value for each row.
Our moving weighted average solution should take the form of the following:
SELECT
student_name,
course_name,
grade,
units,
ROUND((SUM(grade*units) OVER (
PARTITION BY student_id
ORDER BY grade_id ROWS
BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) / SUM(units) OVER (
PARTITION BY student_id
ORDER BY grade_id ROWS
BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)), 3)
AS 'Running Average Grade'
FROM
Students
JOIN
Grades ON Students.student_id = Grades.student_id
ORDER BY
grades.student_id, grade_id;
Figure 3.0: Window Function Solution for Calculating the Moving Average
While this might look intimidating at first glance, we’ll break it down step-by-step below.
Window Functions with the General Form
The modified version of the general form in this query is:
ROUND((SUM(grade*units) OVER (
PARTITION BY student_id
ORDER BY grade_id ROWS
BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) / SUM(units) OVER (
PARTITION BY student_id
ORDER BY grade_id ROWS
BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)), 3)
AS 'Running Average Grade'
Figure 3.1: The Modified General Form from Figure 3.0
Still quite a big chunk, isn’t it? We can express the general form G SELECT (SUM(value * weight) / SUM(weight)) into two parts, G₁ SUM(value * weight) and G₂ SUM(weight).
Similarly, we can express the modified general form (see Figure 3.1) as G’ into two parts:
G’₁ :
(SUM(grade*units) OVER (
PARTITION BY student_id
ORDER BY grade_id ROWS
BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) /
and G’₂ :
SUM(units) OVER (
PARTITION BY student_id
ORDER BY grade_id ROWS
BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
Note, the code snippet SUM(value*weight) from G₁ is still in G’₁ as SUM(grade*units) . The same thing is true with G₂ . What makes them different are our complex window functions. Window functions are declared using the OVER keyword, typically after an aggregation function (which in this case is SUM).
A window function is defined by three sections: PARTITION BY, ORDER BY, and the window frame.
PARTITION BY student_idmeans that the window is defined for each uniquestudent_idand the calculation is performed separately for each student.ORDER BY grade_idspecifies the order in which the rows are considered within each partition. Here, the rows are ordered by thegrade_idcolumn.ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROWis our window frame and it defines the range of rows included in the calculation. We can read this like plain English and understand that we start the calculation from the beginning of our partition (specified byUNBOUNDED PRECEEDING) up until the current row.
Let’s see this in action.
- For
PARTITION BY, the results will look largely equivalent to Figures 2.1 and 2.2, as partitions function similarly toGROUP BY.
| student_id | grade_id | student_name | course_name | grade |
|---|---|---|---|---|
| 1 | 1 | John Smith | Mathematics | 3.50 |
| 1 | 2 | John Smith | Physics | 4.00 |
| 1 | 3 | John Smith | English | 3.80 |
| 2 | 4 | Jane Doe | Chemistry | 3.90 |
| 2 | 5 | Jane Doe | Biology | 3.70 |
Figure 3.2: Table before PARTITION BY
| student_id | grade_id | student_name | course_name | grade |
|---|---|---|---|---|
| 1 | 1 | John Smith | Mathematics | 3.50 |
| 1 | 2 | John Smith | Physics | 4.00 |
| 1 | 3 | John Smith | English | 3.80 |
| student_id | grade_id | student_name | course_name | grade |
|---|---|---|---|---|
| 2 | 4 | Jane Doe | Chemistry | 3.90 |
| 2 | 5 | Jane Doe | Biology | 3.70 |
Figure 3.3: Tables after PARTITION BY
- We then have the
ORDER BYclause, which means we’ll run the window aggregation in the specified order. In this case, we order them bygrade_id. - Using our window frame definition, we should have the following happen when running our query:
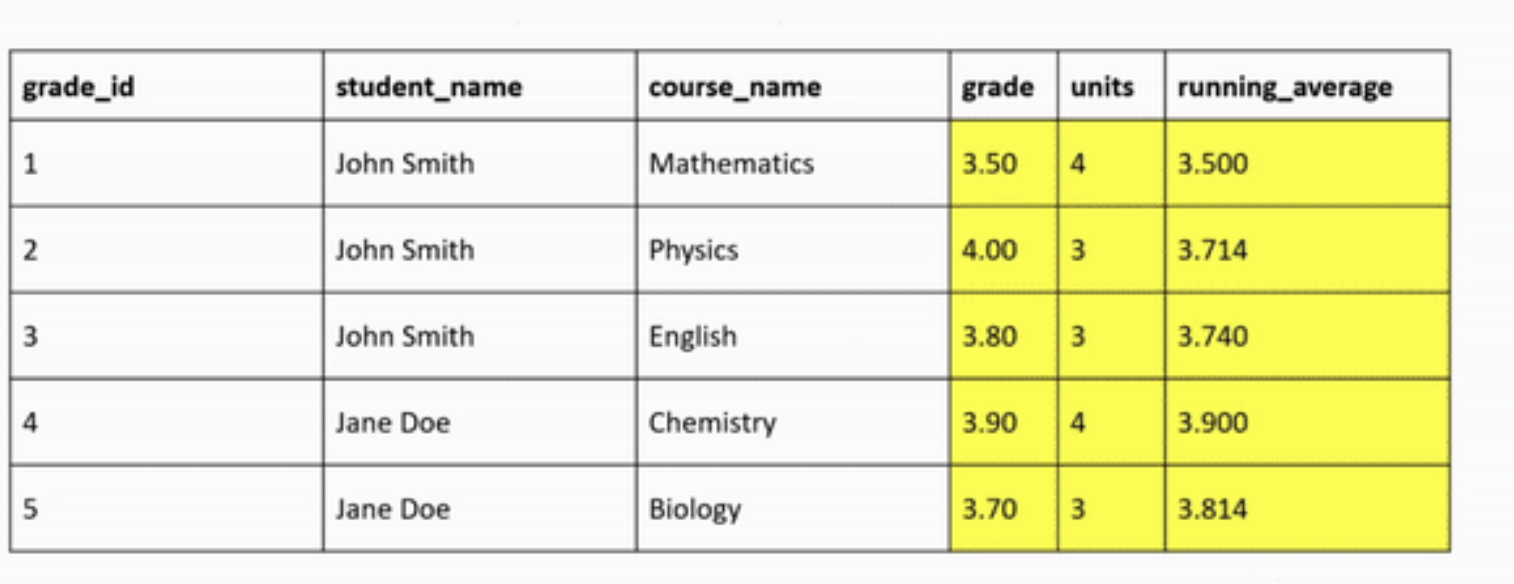
Figure 3.4: Window Function Aggregation Visualization
The aggregation will be performed on each partition separately. In this case, we have two partitions: Partition 1 (consisting of grade_id 1 to 3) and Partition 2 (for grade_id 4 to 5).
The window function aggregation will consider the order of the rows based on the grade_id column. It’ll start the calculation from the beginning of each partition as defined by UNBOUNDED PRECEDING and continue up to the current row within the window.
Let’s focus on Partition 1 as an example. When the window function is performed on the second row (grade_id 2), it’ll calculate the values starting from the beginning of the partition (grade_id 1) up to the current window, which is grade_id 2.
Therefore, the results of our query should look like this:
| student_name | course_name | grade | units | Running Average Grade |
|---|---|---|---|---|
| John Smith | Mathematics | 3.50 | 4 | 3.500 |
| John Smith | Physics | 4.00 | 3 | 3.714 |
| John Smith | English | 3.80 | 3 | 3.740 |
| Jane Doe | Chemistry | 3.90 | 4 | 3.900 |
| Jane Doe | Biology | 3.70 | 3 | 3.814 |
| Michael Johnson | History | 3.20 | 3 | 3.200 |
| Michael Johnson | Geography | 3.50 | 4 | 3.371 |
| Emily Williams | Computer Science | 3.90 | 4 | 3.900 |
| Emily Williams | Art | 3.20 | 2 | 3.667 |
| Daniel Brown | Psychology | 3.60 | 3 | 3.600 |
| Daniel Brown | Sociology | 3.80 | 3 | 3.700 |
| Olivia Davis | Economics | 3.40 | 4 | 3.400 |
Figure 3.5: Results of the Moving Average Query
Practice Weighted Average SQL Questions
In this section, we’ll solve three of the most common SQL weighted average interview questions.
Let’s find out how many you can solve correctly!
1. Weighted Average Email Campaign
Question
A marketing team is doing a review of their past email campaigns and they’re interested in understanding the effectiveness of each campaign. They’ve collected data on the number of users who opened each email and the number of users who clicked on a link within the email. They want to compute a weighted average score for each campaign where the weight of the open rate is 0.3 and the weight of the click rate is 0.7.
Write a SQL query to calculate the weighted average for each campaign.
Note: The weighted average should be rounded to two decimal places.
Example:
Input:
email_campaigns table
| Column | Type |
|---|---|
| campaign_id | INTEGER |
| campaign_name | VARCHAR |
| num_users | INTEGER |
| num_opens | INTEGER |
| num_clicks | INTEGER |
Output:
| Column | Type |
|---|---|
| campaign_name | VARCHAR |
| weighted_avg | DECIMAL(4,2) |
Solution
The query for this problem should include:
SELECT
campaign_name,
ROUND(
(0.3 * (num_opens / num_users)) +
(0.7 * (num_clicks / num_users)),
2) AS weighted_avg
FROM
email_campaigns;
Figure 4.1: Preliminary Solution for Weighted Average Email Campaign
The query first calculates the open rate (num_opens / num_users) and click rate (num_clicks / num_users). The weighted average is then calculated using 0.3 for the weight of the open rate and 0.7 for the click rate.
Notice that we didn’t need to divide the sum by the SUM of the weights. This is because the weights in this question are percentiles, so we can directly multiply the weight by the value without dividing the total by the sum of the weights.
Note that, in SQL, dividing two integers results in an integer. If num_users, num_opens, and num_clicks are integers, you should convert them to float to get the correct result. This is especially important when dealing with ratios or percentages.
With the conversion, the query should look like:
SELECT
campaign_name,
ROUND(
-- casting to assure that we get the correct division result
(0.3 * (CAST(num_opens AS DECIMAL(10,2)) / CAST(num_users AS DECIMAL(10,2)))) +
(0.7 * (CAST(num_clicks AS DECIMAL(10,2)) / CAST(num_users AS DECIMAL(10,2)))),
2) AS weighted_avg
FROM
email_campaigns;
Figure 4.2: Corrected Solution for Weighted Average Email Campaign with Unaccounted Edge Cases
However, as it stands, this query can’t handle a situation where num_users is 0, which would cause a dividing by zero error.
We can prevent this by introducing a conditional clause:
SELECT
campaign_name,
-- introducing a conditional clause to avoid a division by zero error
IF(num_users > 0,
ROUND(
(0.3 * (CAST(num_opens AS DECIMAL(10,2)) / CAST(num_users AS DECIMAL(10,2)))) +
(0.7 * (CAST(num_clicks AS DECIMAL(10,2)) / CAST(num_users AS DECIMAL(10,2)))),
2),
0) AS weighted_avg
FROM
email_campaigns;
Figure 4.3: Full Solution
In this version, if num_users is greater than 0, it calculates the weighted average as before. If num_users is 0, it simply returns 0 as the weighted average.
2. Rolling Weighted Average Sales
Question
The sales department is conducting a performance review and is interested in trends in product sales. They’ve decided to use a weighted moving average as part of their analysis.
Write a SQL query to calculate the 3-day weighted moving average of sales for each product. Use the weights 0.5 for the current day, 0.3 for the previous day, and 0.2 for the day before that. Round the average to two decimal points.
Note: only output the weighted moving average for dates that have two or more preceding dates. You may assume that the table has no missing dates.
Example:
Input:
sales table
| Column | Type |
|---|---|
| date | DATE |
| product_id | INTEGER |
| sales_volume | INTEGER |
Output:
| Column | Type |
|---|---|
| date | DATE |
| product_id | INTEGER |
| weighted_avg_sales | FLOAT |
Solution:
Your answer should look something like the following query:
WITH weighted_sales AS (
SELECT
date,
product_id,
sales_volume,
-- Calculate the weighted average sales using the sales_volume of the current row and the two previous rows
(0.5 * sales_volume +
0.3 * LAG(sales_volume, 1) OVER (PARTITION BY product_id ORDER BY date) +
0.2 * LAG(sales_volume, 2) OVER (PARTITION BY product_id ORDER BY date))
AS weighted_avg_sales,
-- Count the number of preceding days (including the current day) within a rolling window of 3 days
COUNT(*) OVER (PARTITION BY product_id ORDER BY date ROWS BETWEEN 2 PRECEDING AND CURRENT ROW)
AS num_preceding_days
FROM
sales
)
SELECT
date,
product_id,
weighted_avg_sales
FROM
weighted_sales
WHERE
-- Count the number of preceding days (including the current day) within a rolling window of 3 days
num_preceding_days = 3
ORDER BY
date,
product_id;
Figure 5.0: Full Solution
We structured our solution in this article using a common table expression (CTE), so let’s focus first on that block. The CTE is referenced as the query inside the WITH ... AS syntax.
There are two critical parts of this query, each aimed at fulfilling a requirement of the question:
- (A) generating the weighted moving average
- (B) only including days with at least two preceding days.
First, let’s dissect the weighted_avg_sales section:
(0.5 * sales_volume +
0.3 * LAG(sales_volume, 1) OVER (PARTITION BY product_id ORDER BY date) +
0.2 * LAG(sales_volume, 2) OVER (PARTITION BY product_id ORDER BY date))
AS weighted_avg_sales
Figure 5.1: Solution for Requirement A
We have three different nested expressions in this block.
0.5 * sales_volumetakes the current day’s sales and applies a weight of 0.5.0.3 * LAG(sales_volume, 1) OVER (PARTITION BY product_id ORDER BY date)calculates the sales volume of the previous day, lagged by 1, within eachproduct_idgroup. TheLAGfunction is used to access the sales volume of the preceding day within eachproduct_idgroup, ordered bydate.0.2 * LAG(sales_volume, 2) OVER (PARTITION BY product_id ORDER BY date)calculates the sales volume of the day before the previous day, lagged by 2, within eachproduct_idgroup.
By calculating their sum, we get their weighted average.
Notice that we did not need to divide the sum by the SUM of the weights. This is because the weights in this question are percentile, so we can directly multiply the weight by the value without dividing the total by the sum of the weights.
For requirement B, we’re interested in the num_preceding_days alias and the WHERE clause in the main query.
The num_preceding_days column represents the count of preceding days within each product_id group. It’s calculated using a window function that counts the number of rows in the window frame, including the current row and the two preceding rows, based on the order of date.
This count determines whether a row is included in the final result set, as only rows with num_preceding_days equal to 3 are selected, as specified in WHERE num_preceding_days = 3.
3. Rolling Weighted Average with Skipped Dates
Question
The analytics team of a platform wants to calculate the 3-day rolling weighted average for new daily users, where the most recent day has a weight of 3, the second-most recent day has a weight of 2, and the third-most recent day has a weight of 1. The team wants to analyze the trend and growth of new daily users over a short period. When the system doesn’t detect any new users by the end of the day, it won’t load that date into the database.
Write a SQL query to calculate the 3-day rolling weighted average for new daily users from the users table. Round the average to two decimal places.
Example:
Input:
stocks table
| Column | Type |
|---|---|
| date | DATE |
| price | DECIMAL |
Output:
| Column | Type |
|---|---|
| date | DATE |
| weighted_avg | DECIMAL |
Solution
-- This CTE is used to calculate the lag offsets and the first date in the dataset.
WITH ordered_users AS (
SELECT
date,
new_users,
LAG(new_users, 1) OVER (ORDER BY date) AS new_users_lag_1,
LAG(new_users, 2) OVER (ORDER BY date) AS new_users_lag_2,
MIN(date) OVER () AS initial_date
FROM
users
),
calculated_users AS (
SELECT
date,
initial_date,
-- This 'CASE WHEN' block does the logic in determining how to calculate a datapoint depending
-- on the date difference from the previous rows.
CASE
WHEN DATEDIFF(date, LAG(date, 1) OVER (ORDER BY date)) = 1 THEN
CASE
WHEN DATEDIFF(date, LAG(date, 2) OVER (ORDER BY date)) = 2 THEN ROUND((3 * new_users + 2 * new_users_lag_1 + new_users_lag_2) / 6, 2)
ELSE ROUND((3 * new_users + 2 * new_users_lag_1) / 6, 2)
END
WHEN DATEDIFF(date, LAG(date, 1) OVER (ORDER BY date)) = 2 THEN ROUND((3 * new_users + new_users_lag_1) / 6, 2)
ELSE ROUND(3 * new_users / 6, 2)
END AS weighted_average
FROM
ordered_users
)
SELECT
date,
weighted_average
FROM
calculated_users
WHERE
-- Ensures that only the dates at least two days from the first day of calculation
-- are added to the result set. We can include the second row, as long as it has
-- skipped a date from the first row.
DATEDIFF(date, initial_date) >= 2;
Figure 6.1: Full Solution
In this query, two CTEs are used to organize and isolate the calculations, as well as to separate our conditional filters from other operations.
The first CTE, ordered_users, is used for data organization and preparation. It performs two significant operations:
- Creates additional columns through the
LAG()function as offsets - Calculates the earliest date in the dataset (
initial_date) using a window function
These are all potentially complicated calculations that are best done separately from the main query for readability and maintenance. This results in the following table:
| date | new_users |
|---|---|
| 2023-01-01 | 100 |
| 2023-01-02 | 50 |
| 2023-01-04 | 80 |
| 2023-01-05 | 120 |
Figure 6.2: Table before the LAG Offsets
| date | new_users | new_users_lag_1 | new_users_lag_2 |
|---|---|---|---|
| 2023-01-01 | 100 | NULL | NULL |
| 2023-01-02 | 50 | 100 | NULL |
| 2023-01-04 | 80 | 50 | 100 |
| 2023-01-05 | 120 | 80 | 50 |
Figure 6.3: Table after the LAG Offsets
The second CTE, calculated_users, is used to compute the weighted average of new users based on the data prepared in the ordered_users CTE. This weighted average is calculated differently depending on the gap between the current date and the previous date(s).
Next, the OVER (ORDER BY date) clause ensures that the rows are ordered by the date column before the LAG() function is applied.
Ideally, we’ll retrieve the date and the corresponding new users from the first CTE and apply the weighted average logic accordingly, as expressed in the code: ( 3 * new_users+ 2 * new_users_lag_1+ new_users_lag_2), represented as G₁ in our general form.
However, note that some dates may be missing. There are several ways to address this, with some more convenient (such as Postgres’ sequence builder) than others. For the most vendor-agnostic solution, we used the CASE WHEN approach:
CASE
-- (A)
WHEN DATEDIFF(date, LAG(date, 1) OVER (ORDER BY date)) = 1 THEN
CASE
-- case 1:
WHEN DATEDIFF(date, LAG(date, 2) OVER (ORDER BY date)) = 2 THEN ROUND((3 * new_users + 2 * new_users_lag_1 + new_users_lag_2) / 6, 2)
-- case 2:
ELSE ROUND((3 * new_users + 2 * new_users_lag_1) / 6, 2)
END
-- (B)
-- case 3:
WHEN DATEDIFF(date, LAG(date, 1) OVER (ORDER BY date)) = 2 THEN ROUND((3 * new_users + new_users_lag_1) / 6, 2)
-- case 4:
ELSE ROUND(3 * new_users / 6, 2)
END AS weighted_average
Figure 6.4: CASE WHEN Block
To walk through how we got the weighted sum for G₁ with the missing dates considered, let’s divide up this block with a decision tree. So, if:
- The date one row back is indeed the day before the current date (A):
- Case 1: check if the row before that is two days before our current row. In that case, we can assume that there are no missing dates. We use
3 * new_users + 2 * new_users_lag_1 + new_users_lag_2to get our weighted sum. - Case 2: If the date two days back is missing and the third date had no new users, so we should only consider the current date and the day before. So, we use
3 * new_users + 2 * new_users_lag_1.
- Case 1: check if the row before that is two days before our current row. In that case, we can assume that there are no missing dates. We use
- On the other hand, we should also check if the date one row before our current row is two days back (B):
- Case 3: If it is, this means that only the day before the current day is missing. Our weighted sum should be calculated as
3 * new_users + new_users_lag_2. - Case 4: If not, this means that all the days prior to our current date are missing. We should evaluate our weighted sum as
3 * new_users.
- Case 3: If it is, this means that only the day before the current day is missing. Our weighted sum should be calculated as
We’ll then divide our weighted sum in G₁ by six, as that is the sum of the weights (3+2+1), which is represented as G₂ in our general form.
Notice that we divided the sum weighted sum by the SUM of the weights because we don’t have percentile weights in this question.
Lastly, we add the WHERE clause, which is a little tricky too. While it’s easy to dismiss the first two rows from our result set, this would be a naïve approach.
Consider a situation wherein the second row is not the day after the first row. This means that it’s logically correct to assume that the second date should be a part of the result set. As such, instead of basing our decision on whether to include the second row based on its placement on the table, we should consider the interval between the first date instead, using DATEDIFF(date, initial_date) >= 2.
4. Random Weighted Driver
Question:
Let’s say we want to improve the matching algorithm for drivers and riders for Uber. The engineering team has added a new column to the drivers table called weighting. It contains a weighted value, which they hope will lead to better matching.
Given this table of drivers, write a query to perform a weighted random selection of a driver based on the driver weight.
Example:
Input:
drivers table
| Column | Type |
|---|---|
id |
INTEGER |
weighting |
INTEGER |
Output:
| Column | Type |
|---|---|
id |
INTEGER |
Solution:
Firstly, we need to take note that the weights are initially integers, but we need to scale them from 0 to 1 for each user, such that the cumulative total sums to 1 (or 100% of all probabilities).
Since the rand() function generates numbers between 0 (inclusive) and 1 (exclusive), we want to somehow split the intervals so that each user has a chance of being picked according to the assigned weight.
Let’s assume that we were given three drivers, and the assigned weights look like this:
| id | weighting |
|---|---|
| 1 | 1 |
| 2 | 4 |
| 3 | 15 |
We can first scale the weights by using the following query (q1):
select id ,
weighting/sum(weighting) over() as scaled_weights
from drivers
| id | scaled_weights |
|---|---|
| 1 | 0.05 |
| 2 | 0.2 |
| 3 | 0.75 |
Once we obtain scaled weights, we can now form the cumulative threshold.
select id, scaled_weights, sum(scaled_weights) over (order by id ) cumulative_th
from
(
select id , weighting/sum(weighting) over() as scaled_weights from drivers
) q1
| id | scaled_weights | cumulative_th |
|---|---|---|
| 1 | 0.05 | 0.0500 |
| 2 | 0.2 | 0.2500 |
| 3 | 0.75 | 1.0000 |
Now we can see the idea behind the cumulative threshold:
- If
rand()generates a number between 0 (inclusive) and 0.05 (exclusive), User 1 is picked. Chance of picking User 1 is 5%. - If
rand()generates a number between 0.05 (inclusive) and 0.25 (exclusive), User 2 is picked. Chance of picking User 2 is 20%. - If
rand()generates a number between 0.25 (inclusive) and 1 (exclusive), User 3 is picked. Chance of picking User 3 is 75%.
We can write a final solution as:
select q2.id from
(
select q1.id, q1.scaled_weights, sum(q1.scaled_weights) over (order by q1.id ) cumulative_th
from
(
select id , weighting/sum(weighting) over() as scaled_weights from drivers
) q1
) q2
where cumulative_th > rand()
order by id
limit 1;
Learn SQL with Interview Query
The best way to get better in SQL is practice. Interview Query offers a variety of SQL learning resources to help you practice and improve your SQL skills, including: