

Revolut Data Analyst Interview Guide: Process, Questions, and Preparation Tips

Introduction
Joining as a Revolut data analyst means diving into fast-paced problem-solving from day one. You’ll build dashboards that track key product metrics, monitor customer behavior, and uncover inefficiencies in user journeys. Your day often includes deep dives into growth funnels to identify drop-offs and levers for improvement. You’ll work closely with product teams to shape features and with risk squads to detect fraud and reduce exposure. The role is both analytical and strategic—your insights directly influence decisions in real time.
Role Overview & Culture
The data analyst Revolut position sits at the heart of a company known for its data-first culture. Revolut lives by its core value: Never Settle. Speed is not just encouraged—it’s expected. Analysts run rapid experiments, iterate on hypotheses, and make calls with imperfect data. That mindset fuels fast learning and faster growth, and ensures data isn’t just reporting the past—it’s defining what comes next.
Why This Role at Revolut?
At Revolut, you’re empowered to influence real-time fraud prevention, shape customer onboarding, and optimize payments infrastructure seen by millions worldwide. The scale of data, combined with the flat structure, means your work has immediate global impact. Internal mobility is rapid—analysts often move into product, strategy, or leadership roles within months. If you’re preparing for the Revolut data analyst interview, you’re already one step closer to working at the center of one of the fastest-moving companies in tech.
What Is the Interview Process Like for a Data Analyst Role at Revolut?
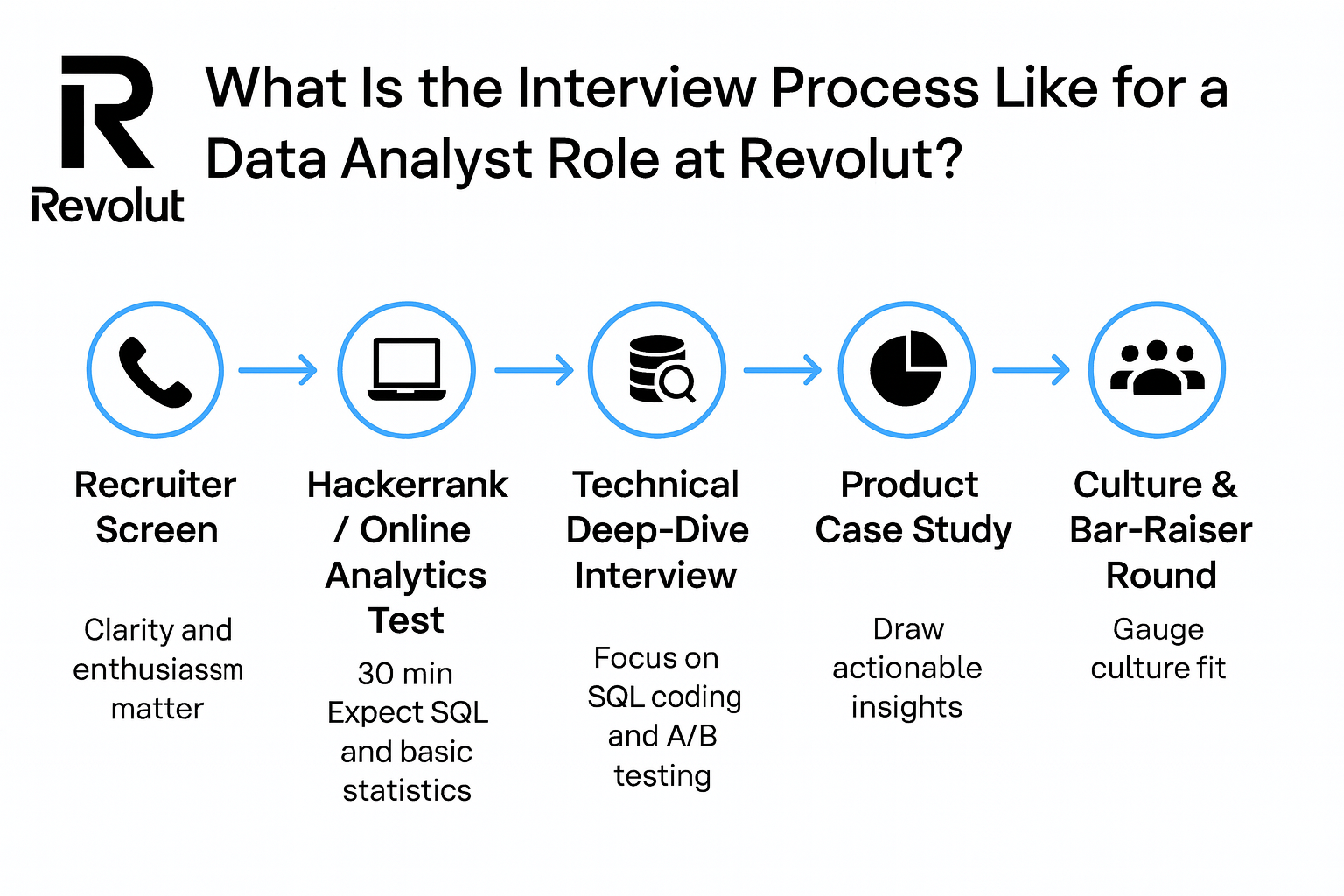
Revolut’s hiring process for data analysts is fast-paced, structured, and designed to assess both technical depth and business impact. Here’s what to expect at each stage.
Recruiter Screen
The process typically kicks off with a short recruiter call. Here, the focus is on your resume alignment, motivation for joining Revolut, and your availability or timeline. While it’s not technical, your clarity and enthusiasm matter—especially in demonstrating why this role fits into your long-term goals.
HackerRank / Online Analytics Test
Next comes the hackerrank data analyst test, a 30-minute timed assessment. Expect a mix of SQL challenges and basic statistics, such as hypothesis testing or interpreting summary data. The bar is high: candidates who score above 70% tend to move forward, so speed and accuracy are key. Practice with real-time SQL editors and review Revolut-style queries ahead of time.
Technical Deep-Dive Interview
After you pass the HackerRank, you will move on to the technical deep-dive stage of the Revolut data analyst interview. It includes live SQL coding where you’re expected to clean, join, and extract insights from raw tables. You may also face an A/B testing scenario—explaining how you’d measure impact, identify sample size, and interpret statistical results under time pressure.
Product Case Study
Next, you’ll be given a mock dataset and asked to draw out actionable insights. This round tests your ability to reason through ambiguous data and communicate clearly with stakeholders. It’s less about technical correctness and more about structure, prioritization, and how well you tell a story with data.
Culture & Bar-Raiser Round
The final stage gauges culture fit. Revolut looks for high ownership and bias-for-action—expect questions like “Tell me about a time you made a decision without all the data.” Strong candidates show initiative, resilience, and the ability to thrive with limited direction.
After each round, a data-science hiring committee evaluates your performance—typically within 24 hours. The process moves fast, and collective feedback ensures consistent quality.
While junior roles focus on execution, senior data analysts are tested on end-to-end experimentation design, influencing product decisions, and handling complex stakeholder trade-offs. Expect more strategy, ambiguity, and leadership scenarios at that level.
Each step builds momentum—so you can focus next on the actual Revolut data analyst interview questions that matter.
What Questions Are Asked in a Revolut Data Analyst Interview?
If you’re preparing for a Revolut data analyst interview, expect a mix of technical, product-focused, and business strategy questions. The interview is designed to assess your SQL skills, analytical thinking, and ability to draw insights that drive decision-making.
SQL & Coding Questions
The Revolut data analyst interview often begins with SQL challenges focused on window functions, sub-queries, and business metrics like churn. Use a clear structure: clarify the problem, write a working solution, then optimize.
1. Write a query to get the total three-day rolling average for deposits by day.
To calculate a three-day rolling average for deposits, aggregate daily deposits, then self-join on the date to include the current and previous two days. Use AVG() to compute the rolling average within this window. This question tests your ability to work with time-based aggregations and rolling metrics—key for trend analysis in fintech.
2. How would you debug a slow SQL query?
This question asks you to diagnose and optimize a poorly performing query, often involving unnecessary joins, lack of indexing, or inefficient filters. Start by reviewing the EXPLAIN plan and look for ways to reduce full table scans or simplify subqueries. It’s designed to assess your real-world debugging skills, especially important in Revolut’s fast-paced, high-volume data environment.
3. Write a query to get the last transaction for each day.
Use a window function like ROW_NUMBER() to assign an order to transactions by date per user, then filter to return only the most recent one. This question tests your grasp of event ordering and row-level filtering, which is foundational for cohort tracking, churn analysis, and user behavior modeling.
4. Find the average number of downloads for free vs paying accounts, broken down by day.
To compare average downloads by free vs. paying users, join the accounts and downloads tables, group by date and account type, and use AVG() to calculate the mean downloads per group. This question tests your ability to perform grouped aggregations and segment metrics by customer type—useful for understanding product engagement by user tier.
5. Write a query to get the top 3 highest employee salaries by department.
Solve this by applying a RANK() function over salaries, optionally partitioned by department if asked, and filtering for ranks ≤ 3. It’s a classic ranking problem that tests your understanding of sorting and window logic—skills vital for leaderboard features, bonus assignment, or compensation analytics.
Product & Experimentation Questions
You’ll be asked to design A/B tests and explain metrics like MDE and retention funnels. Expect to discuss KPIs such as card activation and FinCrime alert reduction.
6. How do you calculate the minimum detectable effect (MDE) in an experiment?
MDE is the smallest effect size that a test can reliably detect, given a fixed power and significance level. You calculate it using the baseline conversion rate, desired power (usually 80%), significance level (typically 5%), and sample size. It helps determine whether your experiment is sensitive enough to detect meaningful changes.
7. How would you analyze the success of a feature that reduces FinCrime alerts but increases false negatives?
The analysis should weigh the trade-off between reducing false positives and the potential risk of missed fraudulent activity. Key metrics to evaluate include false positive rate, false negative rate, precision, recall, and the total financial impact of undetected fraud. A successful feature would maintain or improve fraud detection accuracy while reducing noise for operational teams.
Having unequal sample sizes in an A/B test doesn’t inherently introduce bias, especially when the smaller group (e.g., 50K users) is still large enough to provide statistical power. However, potential bias can arise if the groups were exposed to different time periods or have significantly different variances. Clarifying test duration and distribution assumptions is essential before drawing valid conclusions.
9. In an A/B test, how can you check if assignment to the various buckets was truly random?
To check if A/B test bucketing was truly random, you can compare user attributes (like gender, geography, or device type), referral sources, and pre-experiment behavior metrics across groups. Statistical tests such as t-tests or chi-square tests help identify imbalances. If unrelated metrics and distributions are consistent between variants, it’s likely that randomization was successful.
Business & Data Storytelling Questions
Revolut values analysts who can translate data into action. Frame insights using the Context–Insight–Action structure to make your recommendations clear and impactful.
10. Describe a data project you worked on. What were some of the challenges you faced?
Strong responses should highlight a project with clear business impact—such as improving a product funnel or automating a report pipeline. Common challenges include messy data, ambiguous stakeholder requirements, or shifting goals mid-project. The best answers demonstrate problem-solving, stakeholder communication, and adaptability under uncertainty.
11. How would you explain a complex SQL query or machine learning output to a product manager?
Effective communication starts with understanding the audience’s context. The candidate should strip out technical jargon, summarize the business logic (“we grouped users by behavior over time”), and explain the impact of the results. Visuals, analogies, or sample user stories often help make complex outputs more digestible.
12. You discover users in one region have significantly lower engagement. What’s your approach?
A good answer begins with validating the data to rule out tracking or sampling issues. Next, it should break down engagement by platform, feature usage, and user demographics to identify where the drop occurs. The candidate should suggest forming hypotheses—such as localization issues or slow app speed—and testing them with further analysis or user research.
13. You’re given a drop in app usage—how would you structure your analysis and present findings to leadership?
Describe a structured approach: segment by user cohorts (e.g., new vs. returning), identify when and where the drop occurred, and correlate it with recent product changes or external factors. Presenting to leadership should involve a concise summary of root causes, clear visuals, and 1–2 actionable recommendations—prioritizing clarity and decision-making.
Behavioral & Culture-Fit Questions
Expect STAR-style questions tied to Revolut’s values like “Think Deeper” and “Never Settle.” Show ownership, speed, and how you collaborate under pressure.
14. Why do you want to work with us?
Align your personal values and goals with the company’s mission. For Revolut, this might include excitement about working at the intersection of finance and technology, interest in a fast-paced, data-driven culture, or the opportunity to solve global-scale problems. The best responses are specific—mentioning Revolut’s products, team structure, or culture—not generic.
15. What are your strengths and weaknesses?
The ideal answer demonstrates self-awareness and growth. You can highlight a strength relevant to the role (e.g., analytical thinking, stakeholder communication) and a weakness that is real but actively being improved (e.g., delegating too little or being overly detail-oriented). Revolut values humility paired with action, so framing the weakness as a learning opportunity is key.
16. How do you embody Revolut’s value of “Think Deeper” in your daily work?
Describe a habit of questioning assumptions and digging beyond surface-level answers. For example, validating anomalies instead of accepting dashboards at face value, or running post-analysis reviews to refine experimentation frameworks. The strongest answers show intellectual curiosity and a bias toward finding root causes, not just reporting metrics.
17. Tell me about a time you made a decision without complete data. What was the result?
In a high-velocity environment like Revolut, decisions often require acting before perfect data is available. Strong answers show how the candidate used proxies, small tests, or intuition backed by past experience to move forward. Interviewers are looking for thoughtful risk-taking, and a willingness to learn and adjust post-decision.
18. Tell me about a time you worked cross-functionally to solve a problem.
Describe collaborating with stakeholders outside their immediate function—such as working with engineers to improve data pipelines or with product managers to define A/B test metrics. Key traits to demonstrate include communication, alignment on goals, and the ability to navigate competing priorities. The best responses include a clear outcome and lessons learned.
How to Prepare for a Data Analyst Role at Revolut
Preparing for a data analyst role at Revolut means going beyond just technical skills. You’ll need to demonstrate speed, clarity, and business impact in everything from SQL queries to stakeholder communication.
Master Timed SQL Drills
Reference online mocks similar to the Hackerrank data analyst test. The assessment is short but intense, so focus on writing clean, efficient queries quickly. Focus on joins, aggregations, and window functions under time pressure.
Practice Experiment Design
Be ready to walk through an A/B test from hypothesis to decision. You’ll need to explain how you chose your metrics, calculated sample sizes, and ensured validity. Revolut values speed and rigor, so highlight trade-offs when working with imperfect data. Brush up on statistical power, lift, and guardrail metrics.
Build Storytelling Slides
Rehearse creating a 5-slide deck that summarizes your analysis. Start with the business question, then show key findings, followed by a recommendation. Make sure every chart answers so what? and ties to an action. Practice delivering insights clearly to a product manager or executive audience.
Collect Culture Stories
Always be prepared with past experiences to answer the common data analyst behavioral questions. Draft one strong example for each Revolut value (e.g., Never Settle, Think Deeper). Be mindful of demonstrating what you did to solve the particular problem and what positive outcome you could extract from it.
Mock Interviews & Feedback
Practice live sessions with peers or join our peer-to-peer mock interviews to enhance your communication skills and refine your approach to behavioral and technical questions. Working through these interviews will help minimize hesitation and reduce anxiety, enabling you to interview confidently.
Conclusion
Preparing for the Revolut data analyst interview means more than just brushing up on SQL—you’ll need to combine technical sharpness, product intuition, and strong communication. Focus on mastering timed drills, structuring experiment design, and refining your storytelling. Don’t forget the cultural fit—those value-based questions are just as important as the coding rounds.
Looking to apply as a Revolut data analyst? Explore more insights and role-specific prep by visiting our software engineer and product manager interview guides.
Need more practice or insider tips? Schedule a mock interview to test your readiness under pressure. Check out our blog for practice prompts, deep dives, and insider strategies to help you get hired.