

Capital One Data Scientist Interview Process & Prep Guide

Introduction
Capital One is a leading financial services company known for its forward-thinking approach to technology and innovation in banking. With a strong commitment to digital transformation, Capital One has positioned itself as a tech-driven company where data plays a central role in shaping customer experiences, optimizing financial products, and managing risk. As a Data Scientist here, you’ll work on high-impact challenges such as credit modeling, fraud detection, and personalization—leveraging advanced analytics and collaborating across interdisciplinary teams. If you’re looking for a role where your work directly influences millions of users and business outcomes, this could be a perfect fit. Let’s take a closer look at what the Capital One data scientist interview process entails and how to prepare effectively.
Role Overview & Culture
Capital One stands out as a financial institution that truly embraces technology and data at its core. Unlike many traditional banks, Capital One has built its infrastructure in the cloud and integrated data science into nearly every function of its business. Data Scientists at Capital One work on high-impact problems, from developing machine learning models that assess creditworthiness and detect fraud to creating recommendation systems that personalize customer experiences. These roles require not only technical fluency in tools like Python, SQL, and Spark, but also the ability to collaborate with engineers, product managers, and stakeholders to bring models into production and evaluate their real-world effectiveness.
What sets Capital One apart is how deeply embedded data is in its decision-making culture. The company has invested heavily in AI and automation, leveraging both supervised and unsupervised learning to optimize financial services in a scalable and responsible way. Data science here isn’t siloed—it’s a strategic function aligned with the company’s core values: innovation, integrity, and collaboration. Data Scientists are expected to approach problems with curiosity, transparency, and a commitment to ethical modeling. Whether you’re designing a credit underwriting algorithm or analyzing customer behavior to inform product strategy, your work directly shapes both business outcomes and user experience. For anyone preparing for the Capital One data scientist interview, understanding this blend of technical rigor and value-driven culture is key to standing out.
Why This Role at Capital One?
Capital One offers a rare blend of scale, complexity, and ownership. As a Data Scientist, you’re not just tuning models—you’re contributing to solutions that affect millions of customers and navigating some of the most sophisticated data systems in the financial services industry. The company’s cross-functional structure means you’ll be working alongside talented engineers, analysts, and business strategists, often taking the lead on end-to-end product initiatives. You might build a model to forecast loan defaults, then present it to senior stakeholders and work with tech teams to deploy it in real-time systems.
Beyond the technical challenges, Capital One emphasizes career development and mobility. Whether you’re early in your career or looking to move into leadership, the company supports growth through mentorship, structured learning paths, and the opportunity to explore different lines of business. This dynamic environment, however, comes with a rigorous and multi-step hiring process. The Capital One data science interview is designed to assess not only technical depth but also business insight and communication skills. In the following section, we’ll break down the full interview process—from recruiter screen to case studies and coding rounds—so you can prepare with confidence.
What Is the Interview Process Like for a Data Scientist Role at Capital One?
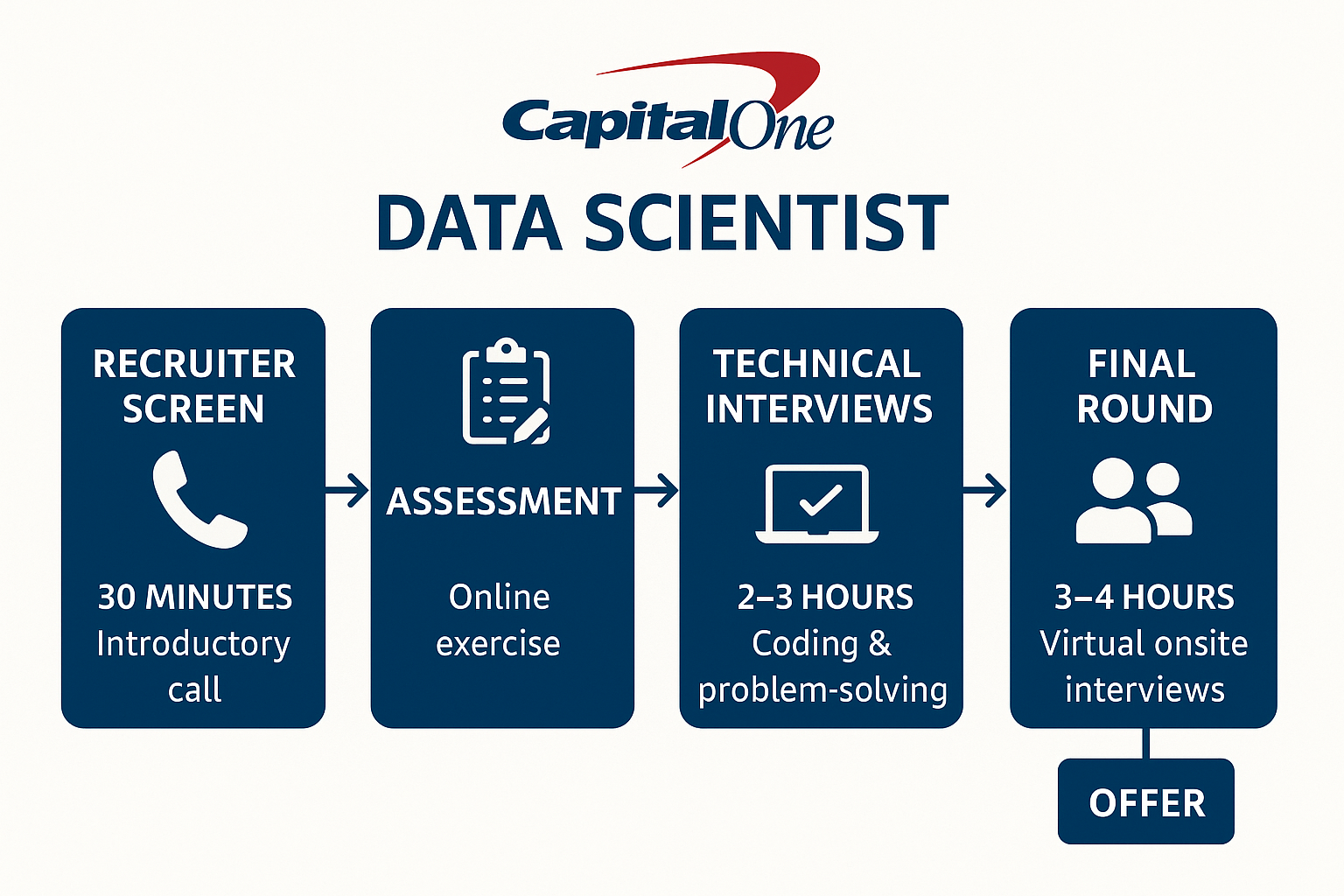
The Capital One data scientist interview process is known for being structured, thorough, and focused on both technical ability and real-world problem-solving. Candidates consistently describe the experience as fair but challenging, reflecting Capital One’s strong emphasis on hiring data professionals who can not only build models but also interpret, communicate, and apply them in a business context. The process typically unfolds over several stages, each designed to evaluate specific skill sets, ranging from SQL and machine learning to business judgment and cultural alignment.
Let’s walk through each stage of the interview so you know exactly what to expect and how to prepare.
Application & Recruiter Screen
The process begins with an online application, often followed by an initial recruiter call if your resume aligns with the role. This 30-minute phone conversation is mostly non-technical and focuses on your background, interest in the position, and basic alignment with the role requirements. Recruiters may ask about your past experience with data science projects, what you’re looking for in your next role, and your familiarity with Capital One’s mission and business. For student candidates or early-career professionals, this is also a chance to discuss timeline expectations and internship conversion potential.
Data Science Challenge
If you pass the recruiter screen, the next step is the Capital One data science challenge, which is one of the most important phases in the process. There are two formats: a timed online technical assessment (such as through CodeSignal) or a multi-day take-home challenge, depending on the role.
For many entry-level and intern candidates, the challenge involves timed SQL and Python questions focused on data manipulation, joins, window functions, and basic analytics. For full-time roles, the take-home version often simulates a real-world machine learning task—such as predicting fraudulent transactions or customer churn—requiring candidates to clean data, build and evaluate models, and present their methodology and results. Candidates often report that the Capital One data science challenge tests both technical fluency and communication: clarity in explaining assumptions, trade-offs, and performance metrics can make a big difference in how submissions are evaluated.
Virtual on-site loop
Candidates who perform well on the challenge are invited to the virtual onsite interview, often referred to as “Power Day.” This intensive session typically consists of three to four interviews, each targeting a different skill set. The technical round assesses your coding and data manipulation abilities, with a focus on SQL queries, statistical reasoning, or walking through a machine learning pipeline using Python. Next, the product-sense or case interview evaluates your ability to approach business problems analytically—you might be asked to estimate the impact of a new credit card feature or design an A/B test, requiring you to frame the problem, outline key metrics, and explain your logic clearly. Another important component is the statistics or machine learning explanation round, which often takes the form of a role play where you present technical findings—such as regression coefficients or model outputs—to a non-technical stakeholder, testing your ability to communicate complex results in an accessible and actionable way. Finally, the behavioral interview explores your alignment with Capital One’s core values like collaboration, ownership, and integrity. You’ll likely be asked to reflect on past experiences involving teamwork, navigating difficult feedback, or managing multiple priorities under pressure.
Hiring committee feedback and decision
After the virtual onsite, Capital One compiles feedback from all interviewers. The hiring committe , typically composed of senior data scientists or cross-functional team leads, reviews these inputs together to reach a consensus. For more senior roles, there may be an additional conversation with a director or hiring manager to evaluate team alignment, leadership qualities, or long-term technical direction. One thing candidates often appreciate is the thoughtfulness of this process: Capital One’s culture emphasizes transparency and fairness, aiming to eliminate bias and ensure every candidate gets a balanced, well-documented evaluation. This collaborative decision-making style reflects the company’s broader culture, where data science, product, and engineering teams work together to shape impactful solutions rather than operating in silos.
Behind the Scenes
Candidates frequently note that Capital One’s process feels well-coordinated and respectful. Interviewers are often described as collaborative rather than adversarial, especially in technical rounds where they may ask guiding questions or prompt you to “think out loud.” The take-home submissions are reviewed carefully, and interviewer feedback is consolidated promptly for hiring committee review. Depending on the role and level, you may also meet a senior data scientist or team lead in a final discussion to assess leadership potential or project alignment.
Differences by Level
The interview structure at Capital One is thoughtfully designed to adapt to the candidate’s level of experience while maintaining a consistent framework across roles.
For entry-level candidates, including interns and recent graduates, the focus tends to be on SQL fluency, foundational statistics, and real-world data wrangling or exploratory data analysis (EDA). These candidates often encounter more guided or structured case questions to help assess analytical thinking in a practical context.
In contrast, mid- to senior-level candidates are expected to engage in deeper technical conversations, especially around modeling strategies, experiment design, and evaluating trade-offs in the context of product or business impact. These interviews often involve open-ended product sense scenarios where strategic thinking and communication play a key role.
For senior or lead roles, additional emphasis is placed on team mentorship, cross-functional collaboration, and stakeholder communication, highlighting leadership potential and the ability to drive data science initiatives at scale.
Regardless of level, the Capital One data science interview is built to assess not just technical knowledge, but how candidates think through problems, communicate their reasoning, and make data-driven decisions. In the next section, we’ll take a closer look at the specific types of questions you can expect and how best to prepare for them.
What Questions Are Asked in a Capital One Data Scientist Interview?
Capital One data scientist interviews focus on coding, case studies, and behavioral questions that test both technical skills and business insight. Here are a few questions to get you going:
Coding / Technical Questions
A key part of the Capital One data scientist interview involves demonstrating technical proficiency through coding and data manipulation tasks. You can expect questions that test your ability to write complex SQL queries using JOINs, CTEs, and window functions, as well as Python or R exercises focused on cleaning, transforming, and analyzing data. These questions are designed to assess how you reason through real-world problems, not just your syntax recall. Interviewers are often looking for a logical thought process, clear assumptions, and an ability to optimize when necessary. In some cases, especially during technical screens or live assessments, the scenario might mimic a typical business use case—such as identifying user churn or evaluating a model’s performance using metrics like ROC-AUC or precision and recall—offering a chance to show how you’d apply your skills in practice during the Capital One data science interview.
1. Group a list of sequential timestamps into weekly lists starting from the first timestamp
Approach this with date arithmetic and slicing in Python. You want to iterate through the list while maintaining buckets that restart every 7 days. Pay attention to edge cases like timezone-aware timestamps or gaps. This question is helpful for assessing your understanding of time series data manipulation, common in analytics roles.
2. Write a function to return the top N frequent words in a list of strings
Use Python’s collections library or a dictionary to count word frequency. Be careful with edge cases like punctuation, case sensitivity, or tied counts. Sorting and efficient use of data structures is key here. This tests your ability to transform raw text into structured data, a crucial step in feature engineering or preprocessing.
3. Write a Pandas function to calculate cumulative test score averages in buckets of 10 points
Use pd.cut() or pd.qcut() to assign buckets and then group by those buckets. Calculate the cumulative average for each bucket using .expanding().mean() or group-based transformations. Visualization can also enhance your understanding. This mirrors real-world tasks like customer segmentation or performance banding.
4. Summarize a dataframe of sales data to show each customer’s top 3 most frequently purchased products
This requires groupby, value_counts, and nlargest or rank functions in Pandas. Make sure to reset indices and handle any missing data. Good indexing and multi-index manipulation are essential. This question demonstrates your ability to extract insights from customer behavior — very applicable to e-commerce and retail use cases.
5. Write a function to remove stop words from a list of strings
Preprocess the input text by lowercasing and tokenizing each sentence. Use a predefined stop word list to filter out common filler words. Return the cleaned version of the string. This task aligns closely with text cleaning work in NLP pipelines or product review analysis.
6. Stem words in a sentence using the shortest root form from a given dictionary
This question requires implementing a simple rule-based stemming algorithm. Use a dictionary to replace longer words with their root if a match exists. Efficient string matching and traversal are critical. Stemming is foundational in natural language processing tasks like search and document classification.
Case & Product-Sense Questions
Capital One places strong emphasis on how well candidates can connect data to business value—making case and product-sense interviews a central part of the Capital One data science interview process. These questions challenge you to reason through ambiguous, real-world scenarios such as estimating the impact of launching a new credit card feature, evaluating a loan default model, or designing an A/B test for a digital banking product. While technical skills are still relevant, this portion of the interview is about strategic thinking, structured problem solving, and communicating trade-offs. You’re expected to clarify business goals, define success metrics, and explain your approach with precision. This is where your ability to combine analytical rigor with customer-centric thinking truly gets tested.
7. Describe how to measure the success of Instagram TV
Begin by defining what “success” means — user engagement, creator adoption, ad revenue, or time spent. Lay out a framework using input, output, and outcome metrics. Suggest KPIs like watch time, repeat views, and upload frequency. This shows your ability to think holistically about product performance and interpret metrics aligned with business goals.
8. Evaluate the effectiveness of a 50% rider discount experiment
Consider the hypothesis: does the discount drive more ridership and increase lifetime value? Break down your approach into treatment/control groups, pre/post metrics, and potential cannibalization effects. Think about unintended consequences such as short-term users exploiting the promo. This type of question tests your ability to design and interpret A/B tests.
9. Determine metrics to assess Mentions app health after celebrity onboarding
Define a set of engagement and retention metrics to track new and existing user behavior. Consider how the influx of celebrities might change the experience or perception for regular users. Identify success in terms of active usage, follower growth, and post interaction. This tests your product intuition and ability to prioritize metric tracking during a high-impact event.
10. Analyze the performance of a new LinkedIn feature that notifies recruiters of active candidates
Structure your analysis around feature adoption, recruiter engagement, and conversion to interviews or hires. Use funnel analysis and track before-and-after behavior for both candidates and recruiters. Be mindful of user privacy or notification fatigue. This reflects real scenarios where data scientists need to evaluate product impact in a B2B platform context.
11. Identify reasons and metrics for decreasing average comments on Instagram
Start by narrowing down the scope — is the trend platform-wide, or limited to specific user segments or content types? Suggest metrics like impressions per post, engagement rate, and algorithmic changes. Use hypothesis-driven analysis to test if changes in UI, audience size, or posting behavior are causes. It evaluates your ability to debug product health issues using data.
12. Determine the percentage of fake news on Facebook based on a data sample
Use sampling and proportion estimation techniques, and suggest a stratified sampling approach if needed. Consider model-based classification vs. human labeling. Evaluate margin of error and confidence intervals. This tests your statistical reasoning and ability to extrapolate insights from partial information.
Behavioral or Culture Fit Questions
In addition to technical and business thinking, Capital One deeply values how candidates align with its core principles—integrity, innovation, collaboration, and customer-first thinking. The behavioral portion of the interview is your chance to demonstrate how you’ve embodied these values in past roles. You might be asked to describe a time your model produced an unexpected result, how you prioritized competing deadlines, or how you navigated a disagreement with a stakeholder. Responses should be concise, reflective, and structured—using the STAR method (Situation, Task, Action, Result) helps keep answers clear and impactful. While these questions may seem softer compared to technical rounds, they are critical to Capital One’s decision-making process and often distinguish top candidates in the Capital One data scientist interview process.
13. Tell me about a time when you had to explain a complex data insight to a non-technical stakeholder.
Start by describing the context of the project and the audience you were addressing. Highlight the techniques you used to simplify technical terms without diluting the meaning. Explain the impact your communication had — such as influencing a decision or aligning the team. This shows your ability to translate analysis into business value, a key trait at Capital One.
14. Describe a situation when you had conflicting priorities or multiple deadlines. How did you handle it?
Walk through how you evaluated urgency and importance, and what frameworks you used to make decisions. Include how you communicated with stakeholders about timelines or trade-offs. If you delegated or automated anything, mention that. This demonstrates time management and your ability to thrive in Capital One’s fast-paced environment.
15. How do you handle feedback — especially if it’s critical or unexpected?
Share a specific example of a time you received tough feedback. Talk about how you processed it, your mindset shift (if any), and the changes you made in response. Show emotional intelligence and a growth-oriented attitude. This aligns with Capital One’s culture of continuous improvement.
16. Tell me about a project where you disagreed with your team’s direction. What did you do?
Describe the situation and your perspective clearly, then walk through how you voiced your opinion respectfully. Focus on how you contributed to the discussion constructively and whether you aligned with the group in the end. Emphasize collaboration and humility. This shows your fit for a cross-functional environment.
17. Have you ever made a mistake in your analysis? What happened and how did you recover?
Own the mistake honestly and show how you caught or were made aware of it. Highlight what actions you took next — such as revising code, informing teammates, or learning a new QA method. End with how this incident improved your diligence or process. This reflects accountability, something Capital One values highly.
18. Describe how you’ve handled working with someone who had a very different communication or work style.
Use an example where you had to adapt or negotiate styles. Talk about how you recognized the difference, what you changed, and how you maintained effectiveness. Mention any feedback you received or gave. This shows adaptability and cultural awareness.
19. Why Capital One? What excites you about working here?
Go beyond generic answers by referring to specific values (like innovation or diversity), projects (like Capital One’s use of machine learning or cloud tech), or culture (like inclusion or customer focus).
How to Prepare for a Data Scientist Role at Capital One
Preparing for the Capital One data scientist interview means building strong foundations not only in technical problem-solving, but also in business acumen and communication. In the financial services industry, data scientists are expected to understand risk, compliance, and customer behavior at scale. At Capital One, this goes even further—models must be not only accurate, but explainable, interpretable, and deployable across mission-critical banking systems. Here’s how to break down your preparation effectively.
Study the Role & Culture
To stand out as a candidate, start by understanding what data science looks like in a financial services context. At Capital One, data scientists work at the intersection of machine learning, regulation, and customer impact. This could mean building fraud detection pipelines, designing credit risk scoring models, or powering real-time personalization engines for digital banking users. These responsibilities demand both a deep technical toolkit and a sensitivity to financial risk and ethical modeling.
Review Capital One’s published use cases in machine learning—particularly in credit, personalization, and fraud prevention. Try to align your past experiences to those themes. For example, if you’ve built a churn prediction model or run an A/B test, think about how those skills would translate to improving customer retention or evaluating new product features in a banking environment. Studying the company’s values—like collaboration, curiosity, and doing the right thing—will help you frame your stories and responses during the interview process.
Practice Common Question Types
An effective preparation strategy involves dividing your time across the major components of the interview: roughly 40% on SQL and coding, 30% on business and product-sense questions, and 30% on behavioral scenarios.
From a technical standpoint, practice SQL problems involving JOINS, CTEs, and window functions—questions you might face in both the initial technical screen and the Capital One data science challenge. Platforms like LeetCode, StrataScratch, and Interview Query offer domain-specific SQL problems relevant to banking analytics, such as detecting duplicate transactions, segmenting high-risk users, or analyzing loan data.
For business and case-style questions, focus on scenarios that are common in financial services. These might include estimating the impact of a new credit card feature, evaluating the ROI of a new underwriting model, or designing an experiment to test loan offer variations. Think through your answers using structured frameworks, and always tie your conclusions back to measurable business outcomes—cost reduction, revenue gain, risk mitigation, or customer engagement.
Think Out Loud & Ask Clarifying Questions
Throughout your interviews—especially in live technical or case-based sessions—it’s important to talk through your thought process clearly and logically. Capital One values candidates who approach problems with structure, transparency, and a collaborative mindset. When presented with an ambiguous prompt, start by stating your assumptions, ask thoughtful clarifying questions, and explain your logic step-by-step. This doesn’t just show technical fluency—it demonstrates professionalism, team orientation, and your ability to work cross-functionally.
Equally important is your ability to communicate with clarity and accessibility. In financial services, data scientists often present results to non-technical partners, like product managers or compliance teams. That means avoiding jargon and explaining models in plain language. For instance, instead of saying “our logistic regression had a strong AUC,” say “the model was effective at distinguishing between likely and unlikely defaulters, which helps us reduce financial risk while maintaining access to credit.”
Brute Force, Then Optimize
Capital One’s interviewers are less interested in perfect solutions than in your ability to reason through messy problems. In both coding and case interviews, it’s okay to begin with a straightforward or even brute-force solution—as long as you show awareness of its limitations and discuss how you would refine it. In data science terms, this might mean starting with a basic decision tree and then discussing how you’d validate and improve it using cross-validation, hyperparameter tuning, or by addressing bias and variance.
This process-first mindset is particularly valuable during the Capital One data science challenge, where candidates are evaluated on how they approach end-to-end modeling problems—including assumptions, feature engineering, and model interpretability.
Mock Interviews & Feedback
Finally, practice like it’s the real thing. Mock interviews are one of the best ways to reduce anxiety, improve fluency, and receive feedback on how you frame your responses. You can use Interview Query mock interview to simulate live questions, or practice with peers who can challenge your explanations and ask follow-up questions. If possible, connect with former Capital One interns or employees through LinkedIn or university networks for tips on what to expect and how to tailor your preparation.
Mock sessions also help you identify weak spots—whether it’s rushing through SQL joins or overcomplicating a business case. Treat each one as a feedback loop, and refine both your content and your delivery. When the real Capital One data science interview comes, you’ll be ready to respond with confidence and clarity.
FAQs
What Is the Average Salary for a Data Scientist Role at Capital One?
Average Base Salary
Average Total Compensation
Where Can I Read More Discussion Posts on Capital One’s Data Scientist Role Here in IQ?
You can find discussion threads, Reddit posts, and reviews from IQ users about Capital One’s data scientist role. These offer helpful insights and real interview experiences.
Are There Job Postings for Capital One Data Scientist Roles on InterviewQuery?
Yes! Interview Query job board regularly updates job listings from top employers, including Capital One. You can browse open Capital One data scientist roles, compare required skills, and apply directly through the platform. Whether you’re seeking full-time, internship, or entry-level opportunities, the job board is a great way to stay current. Explore real openings and prepare with confidence by visiting the Capital One careers page.
Conclusion
Capital One data scientist interview is widely regarded as one of the more structured and thoughtful interview processes in the industry. While it is rigorous—testing everything from SQL and machine learning fundamentals to business reasoning and communication—it’s also entirely navigable with focused, strategic preparation. Understanding the financial context in which Capital One operates, practicing real-world case problems, and refining how you communicate your analytical process will go a long way in setting you apart.
Whether you’re just starting your prep or already deep in mock interviews, keep sharpening your skills across technical, product, and behavioral dimensions. Interview Query can help you simulate the real experience, connect with peers, and access questions that mirror the actual Capital One data science interview format. Ready to take the next step? Explore our other company guides, dive into case walkthroughs, or start your first mock session today.